

Cloze-Driven Pretraining of Self-Attention Networks Summary
Cloze-Driven Pretraining of Self-Attention Networks Summary
This paper introduces a new pre-training method for bidirectional transformers that improves performance on a variety of language understanding problems.


Their significant achievements are:
Large performance gain on GLUE
New SOTA in NER and constituency parsing
Prerequisites
Let’s go over some requirements before we dive deeper in the paper.
Cloze-reading: Task where you fill in the blanks in a passage. For example given the sentence This is a research paper, the idea is to predict the word “research” given “This is a” and “paper”
Transformers: Check this awesome blog if you need a refresher on transformers.
Introduction
The paper dictates that previous bi-directional training was done using independant loss function for each direction. The idea is to jointly pre-train both directions.
They create a bidirectional transformer that’s trained to predict every token in training data. They do this using a cloze-style training objective where the model has to predict the center word given left-to-right and right-to-left context.
Model separately computes forward and backward states with masked self attention architecture.
The Two Tower model
The cloze model represents a probability distribution p(ti|t1,…,ti−1,ti+1,…,tn) for a sentence with n tokens t1, . . . , tn. There are two self- attentional towers each consisting of N stacked blocks: the forward tower operates left-to-right and the backward tower operates in the opposite direction.
To predict a token, we combine the representations of the two towers, as described in more detail below, taking care that neither representation contains information about the current target token.
The forward tower computes the representation Fil for token i at layer l based on the forward representations of the previous layer Fl−1 via self attention; the backward tower computes representation Bil based on information from the opposite direction Bl−1.
Block Structure
Each Block is composed of two sub-blocks:
● The first is a multi-head self attention block with H=16
● The second is a FFN
Position is encoded via fixed sinusoidal position embeddings (same as transformers) and they use a character CNN encoding of the input tokens for word-based models (details here)
In short, words are broken into characters and character embeddings are generated using Conv1D layers of different filter sizes then max pooling layer and highway network are applied to get the final word embedding.
● They apply layer normalization before the two sub-blocks => leads to more effective training
● The input embedding is shared between the two model
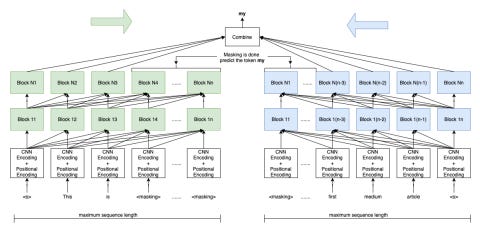
Combination
The output of the two towers is fed into a self-attention module that’s followed by FFN and then softmax activation of size V (V is the vocabulary size)
When the model predicts token i, the input to the attention module are forward states FL1…FLi-1 and backward states Bi+1 . . . Bn where n is the length of the sequence and L is the number of layers. (This is done by masking B≤Li and F≥Li )
The attention query for token i is a combination of FLi-1 and BLi+1. For the base model they sum the two representations and for the larger models they are concatenated.
Fine Tuning
For fine tuning, these changes are made:
● All the tokens of the input sentences are fed into both towers
● The softmax layer is removed and we access the output of the model using the boundary token <s>
● When the input is 2 sentences, we use <sep> token to separate between them
● For fine-tuning, it’s beneficial to remove masking of the current token in the final layer that pools the output of the two towers.
Datasets used
Common Crawl: 9B tokens
News Crawls: 4.5B words
Book Corpus+Wikipedia: 800M words plus English Wikipedia data of 2.5B words (same as BERT)

Results
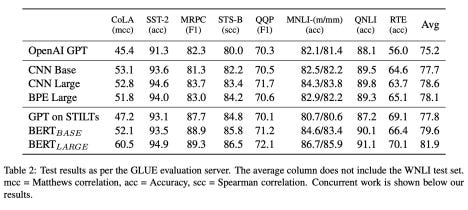
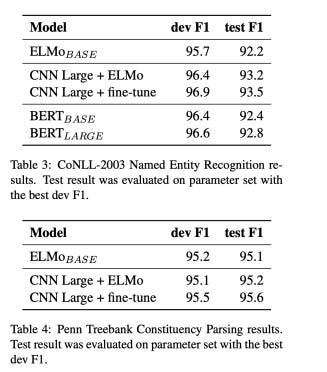
NER Results
To evaluate NER, they use CoNLL-2003 dataset as well as Penn Treebank.
Clap, Follow and Comment if you like the article!
Stay In touch by connecting via LinkedIn Aziz Belaweid or GitHub.