

Does ZEPHYR 7B Outperform 70B LLama-2 Chat?
Does ZEPHYR 7B Outperform 70B LLama-2 Chat?
Zephyr 7B is a model released by HuggingFace. According to the technical report Zephyr-7B outperforms LLama2-Chat on MT-Bench dataset.

In this article, I will go through the differences between this model and the other models, the datasets and techniques used for training, evaluation datasets and results and finally my personal critiques.

What is Different About Zephyr
Zephyr 7B starts off with Mistral 7B as a base model since it is the strongest open source 7B model at the time of writing.
There are no changes in terms of model’s architecture, the changes impact the finetuning and alignment stage.
Starting off with Mistral 7B weights with no further pretraining, Zephyr adds three steps, Distilled Supervised Finetuning(dSFT), AI feedback(AIF) and Distilled Direct Policy Optimization(dDPO).
The whole process looks like this:
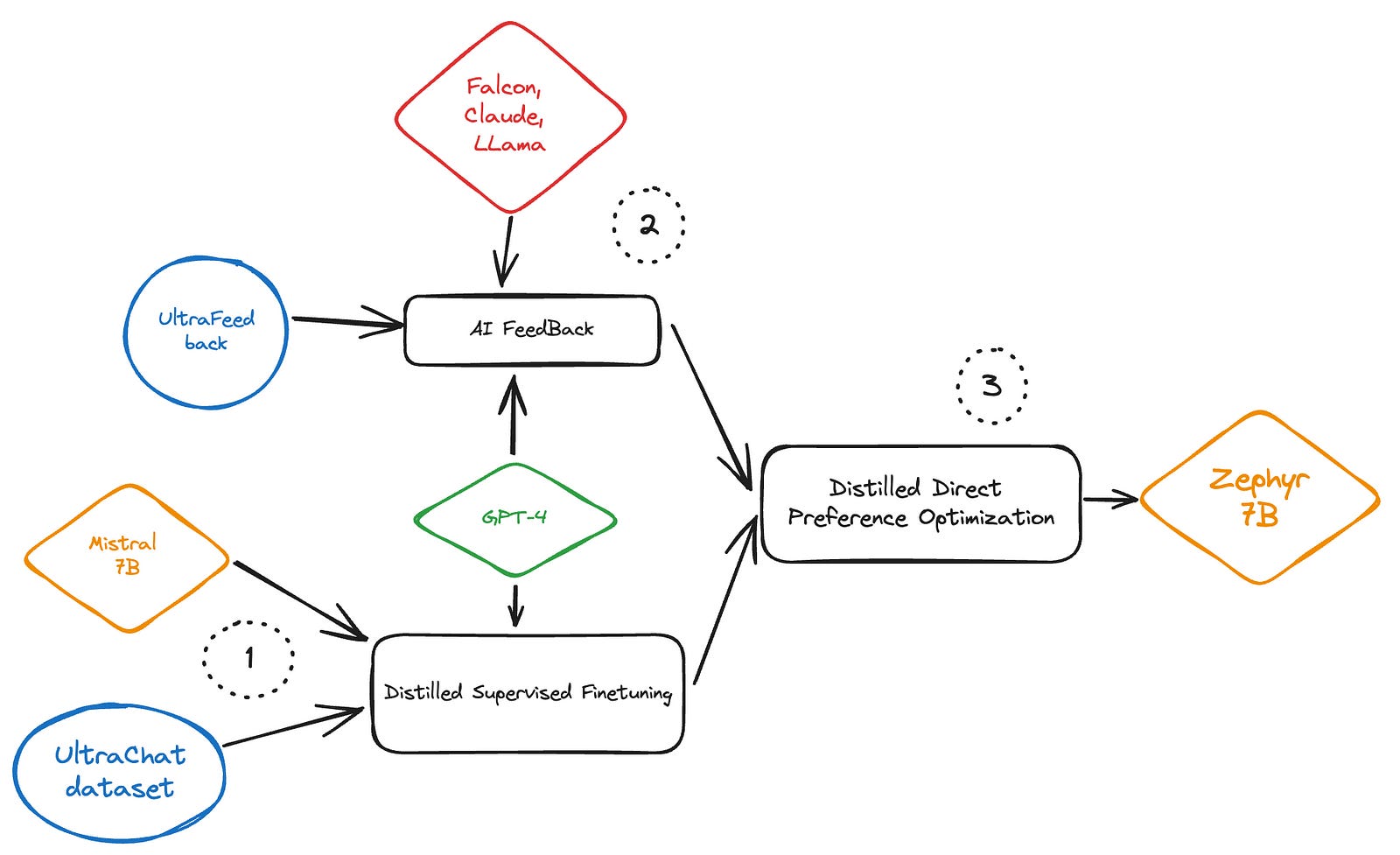
Let’s dismantle it step by step.
Distilled Supervised Finetuning (dSFT)
Starting with a raw LLM Mistral 7B, the goal is to align it to respond to user queries in a human like way. The usual way to do this is to provide pairs of prompts and answers. Using these prompts and answers we can finetune this LLM. This is referred to as Supervised finetuning. What about the “Distilled” part?
The distillation part comes from using a bigger, better model to provide these instructions/responses.
This reduces the effort to manually create these sets, it’s also much faster but comes as a cost of either paying inference API to OpenAI, Cohere, Anthropic… or hosting your own stronger LLM.
The dataset used in UltraChat is generated in self-instruct way using GPT 3.5-Turbo and contains over 30 topics. After cleaning and removing grammatical errors we end up with 200k multi turn conversations which we use to do dSFT.
Training Details:
Epochs: 3
Scheduler: Cosine learning with peak of 2e-5 and 10% warm up steps.
Batch Size: 512
Sequence Length: 2048
AI Feedback (AIF)
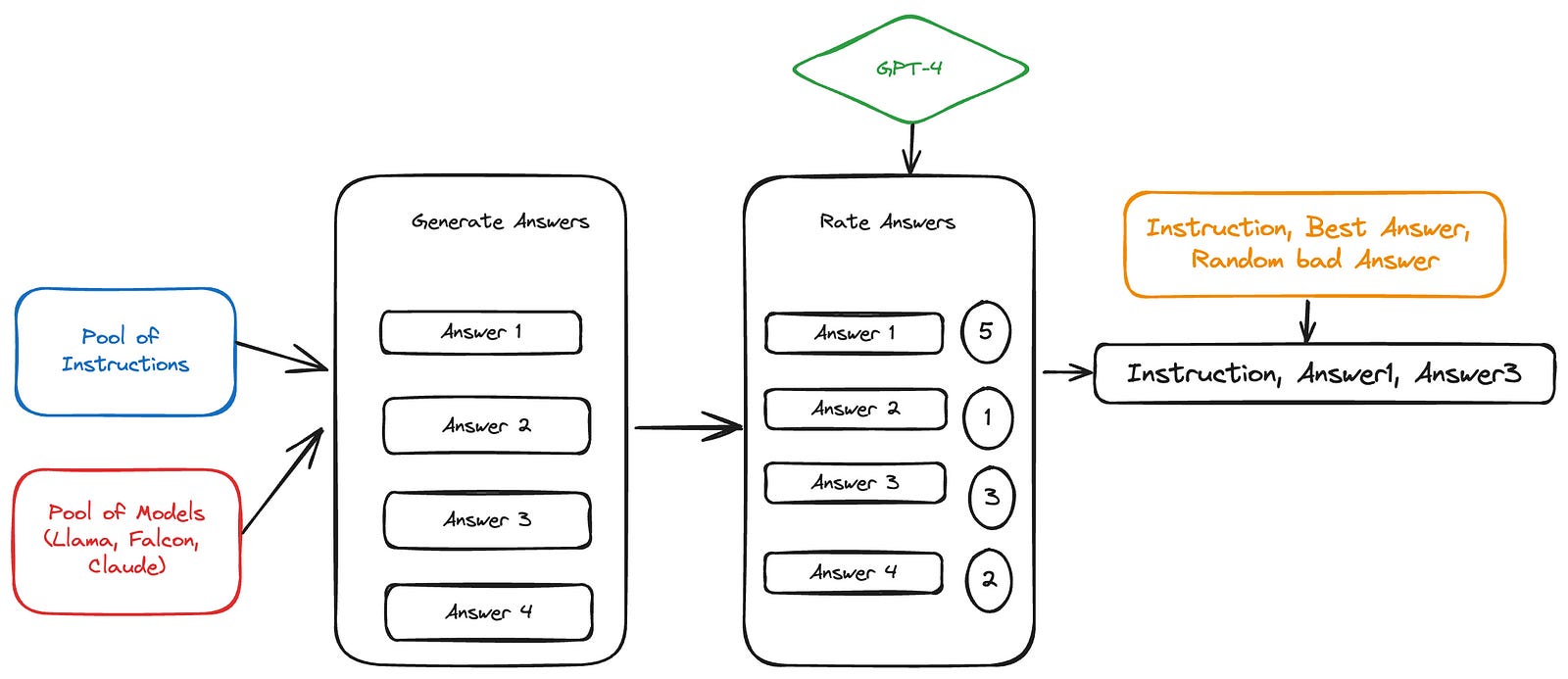
After we taught the model to respond to instructions, we know we need the model to know about preference. By preference we mean, if we had answer A and answer B and they are both correct answers which is the better answer and how do we get the model the choose it in comparison to other answers.
UtraFeedback dataset comes to play here. This dataset contains 64K prompts, for every prompt we generate 4 responses by 4 different LLMs. In the paper they mention Llama, Claude and Falcon (Yes they didn’t mention the fourth LLM).
The 4 responses are then scored by GPT4, the final form of the dataset is multiple triplets containing the prompt, the best answer and a random answer from the other three.
Distilled Direct Policy Optimization (dDPO)
Finally we’ll use the finetuned model and the preference data from previous AIF step to teach the model to maximize the likelihood of the preferred response over the randomly chosen one.
Usually human or AI feedback is used with reinforcement learning to achieve this step. More specifically proximal policy optimization(PPO) is used.
DPO uses a simpler approach, it skips the reward modelling step, so this means you don’t create a model that simulates the reward but instead you directly optimize the language model using preference data.
DPO proposes a good alternative for RLHF which is hard to implement. DPO paper suggests that optimizing the policy directly with preference data is equivalent to training a reward model and then using it to train the policy.
Training Details:
Epochs: 1 to 3
Scheduler: Linear Rate Scheduler with peak of 5e-7 and 10% warm up steps.
Batch Size: 32
Evaluation Results
MT-Bench the dataset used for evaluation is a set of 160 questions across many areas of knowledge. The model needs to answer a first question and then it is given a follow up question to answer as well. The result is then rated by GPT-4 on a scale of 1 to 10.
AlpacaEval set of 805 questions on different topics. The models are again scoed by GPT-4.

We can directly see that the Zephyr 7B model outperforms all the other models of the same size, we can also say for most of the other models beside GPTs, Claude, WizardLM, XwinLM on the two datasets MT-Bench and AlpacaEval.
Both MT-Bench and AlapacaEval need GPT-4 for evaluation which I think biases results since it favours models that have been trained/distilled from the GPT family. The number of questions used in both tests, I also believe is low especially for MT-Bench, only 160 questions is maybe not enough to cover the model’s knowledge or/and alignment.
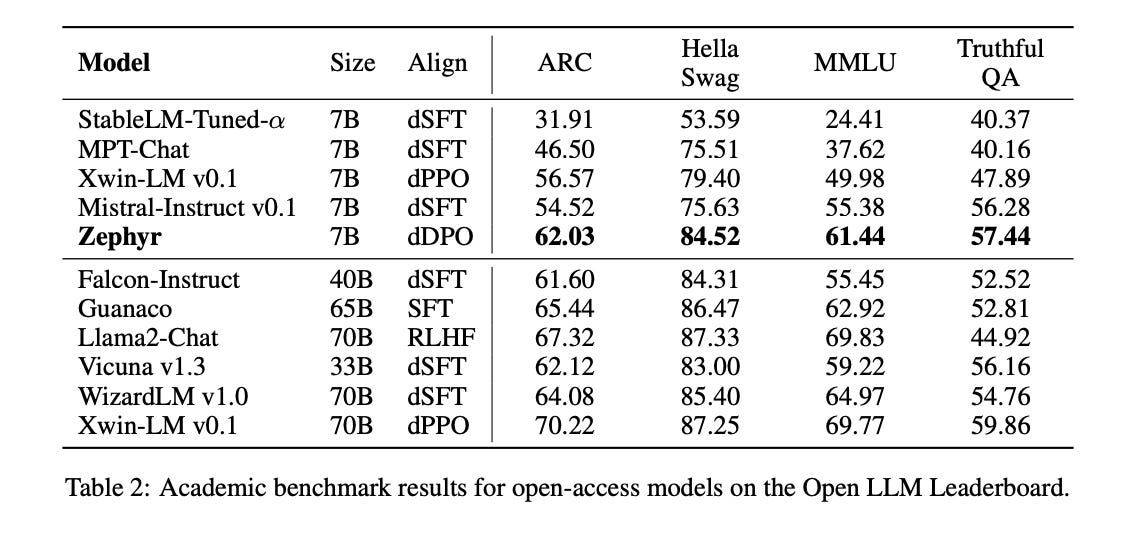
Same as we saw above, we can see Zephyr 7B outperforming all 7B models and also Falcon-Instruct which is 40B. But here we need to keep in mind that this 40B model was only dSFT tuned and not also with dDPO so this is not a direct comparison, we can also say the same about other models.
Using the OpenLLM Leaderboard helps us understand the model more and alleviates the doubts about GPT-4 bias as a judge.
Ablation studies indicate that both dSFT and dDPO are needed and in that specific order to achieve optimal performance.
Even though Zephyr 7B seems good in terms of alignment and can compete with much bigger models, I’m interested in knowing how does it compare depth wise in terms of answering questions that require deep knowledge.
So to answer the question Does ZEPHYR 7B Outperforms 70B LLama-2 Chat?
I say, we don’t know, it might in terms of alignment but in terms of actual knowledge I don’t think so. Zephyr is impressive in my opinion being 10x smaller but still competing in terms of alignment.
If you would like to take Zephyr for a spin, you can try it here.
References
[1] Lewis Tunstall, Edward Beeching, Nathan Lambert, Nazneen Rajani, Kashif Rasul, Younes Belkada, Shengyi Huang, Leandro von Werra, Clémentine Fourrier, Nathan Habib, Nathan Sarrazin, Omar Sanseviero, Alexander M. Rush, Thomas Wolf. (2023) Zephyr: Direct Distillation of LM Alignment http://arxiv.org/abs/2310.16944
[2] HuggingFace Zephyr Model Card. https://huggingface.co/HuggingFaceH4/zephyr-7b-alpha
[3] Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, Chelsea Finn. (2023) Direct Preference Optimization: Your Language Model is Secretly a Reward Model https://arxiv.org/pdf/2305.18290.pdf
Clap, Follow and Comment if you like the article!
Stay In touch by connecting via LinkedIn Aziz Belaweid or GitHub.