

DoRA is The New LoRA!
DoRA is The New LoRA!
The true strength of LLMs lies in how we can employ them for our own needs using our specific data. Various challenges arise when attempting this.

Typically, the strategy to adopt involves transfer learning or fine-tuning. This entails training parts or all of the layers on the new data with a very small learning rate.
When dealing with LLMs, we’re dealing with billions of parameters. This makes it very difficult to store the gradient for all of them. Even if we freeze many parameters and choose to train some, we’re still dealing with training millions of parameters.
To address these challenges, Parameter-Efficient Fine-Tuning (PEFT for short) emerged to assist in fine-tuning LLMs. PEFT incorporates several techniques such as adapters, prompt-based soft tokens, and LoRA.
Among these techniques, the LoRA method has become widely adopted because it adds no inference overhead compared to adapters. It’s a simple and effective fine-tuning technique. Let’s discuss it further.
What is LoRA?
LoRA stands for Low Rank Adaptation. We’ll understand what that means shortly. First, let’s delve into the concept of adaptation.
We’ve established that training the entire LLM isn’t feasible because of the vast number of parameters and gradients. Another issue arises once we start fine-tuning: we can’t revert to the original model if we need to.
The concept of adaptation involves adding an adapter module (a set of weights) in parallel to the original weights. Then, during fine-tuning, we only train the adapter module while keeping the original weights of the LLM frozen.
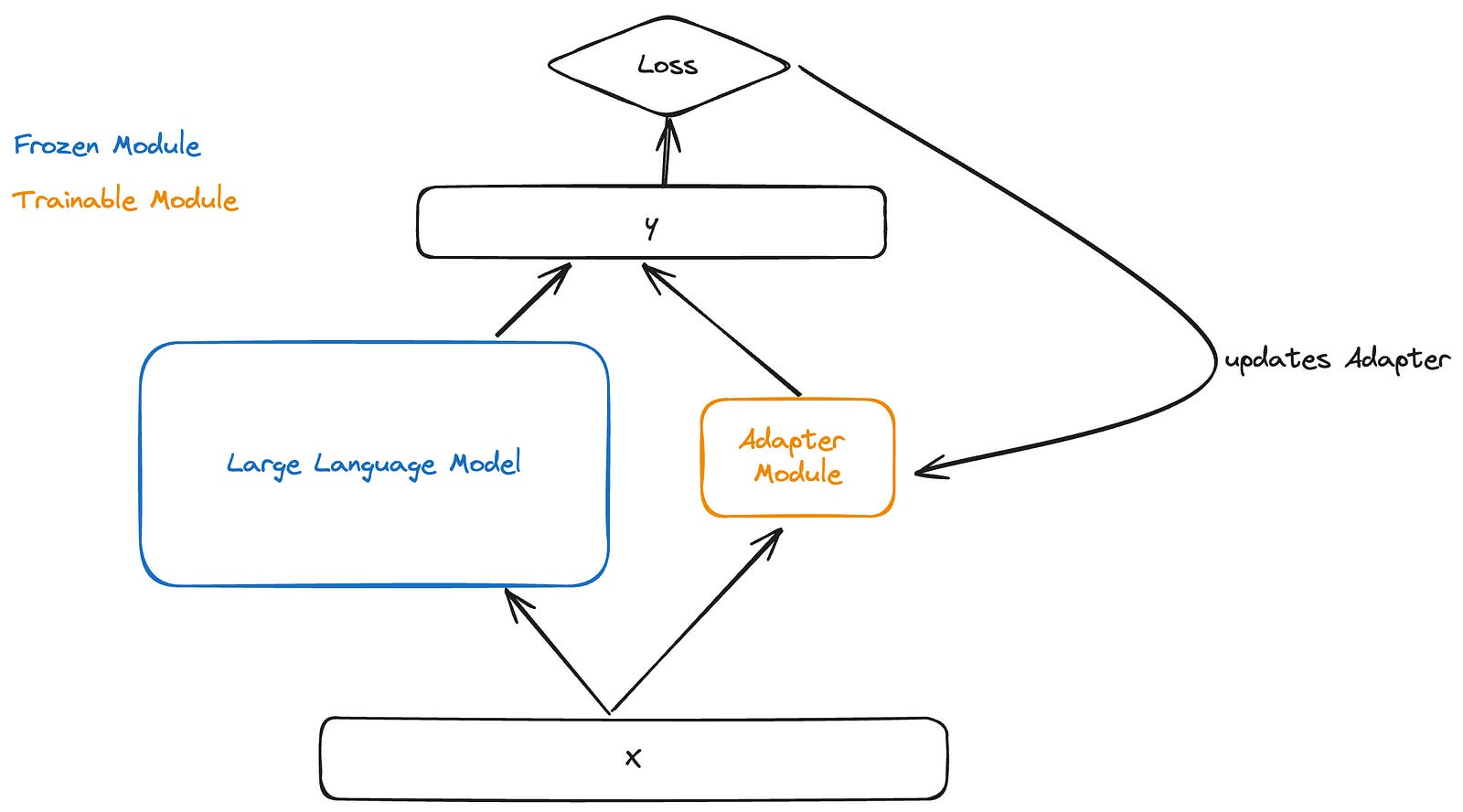
The good thing here is that we now have a small adapter module that we can train for a new task while also keeping the original model intact. You can think of the adapter module as a plugin that we can add or remove. However, the drawback of this approach is that we end up with extra adapter module weights during inference.
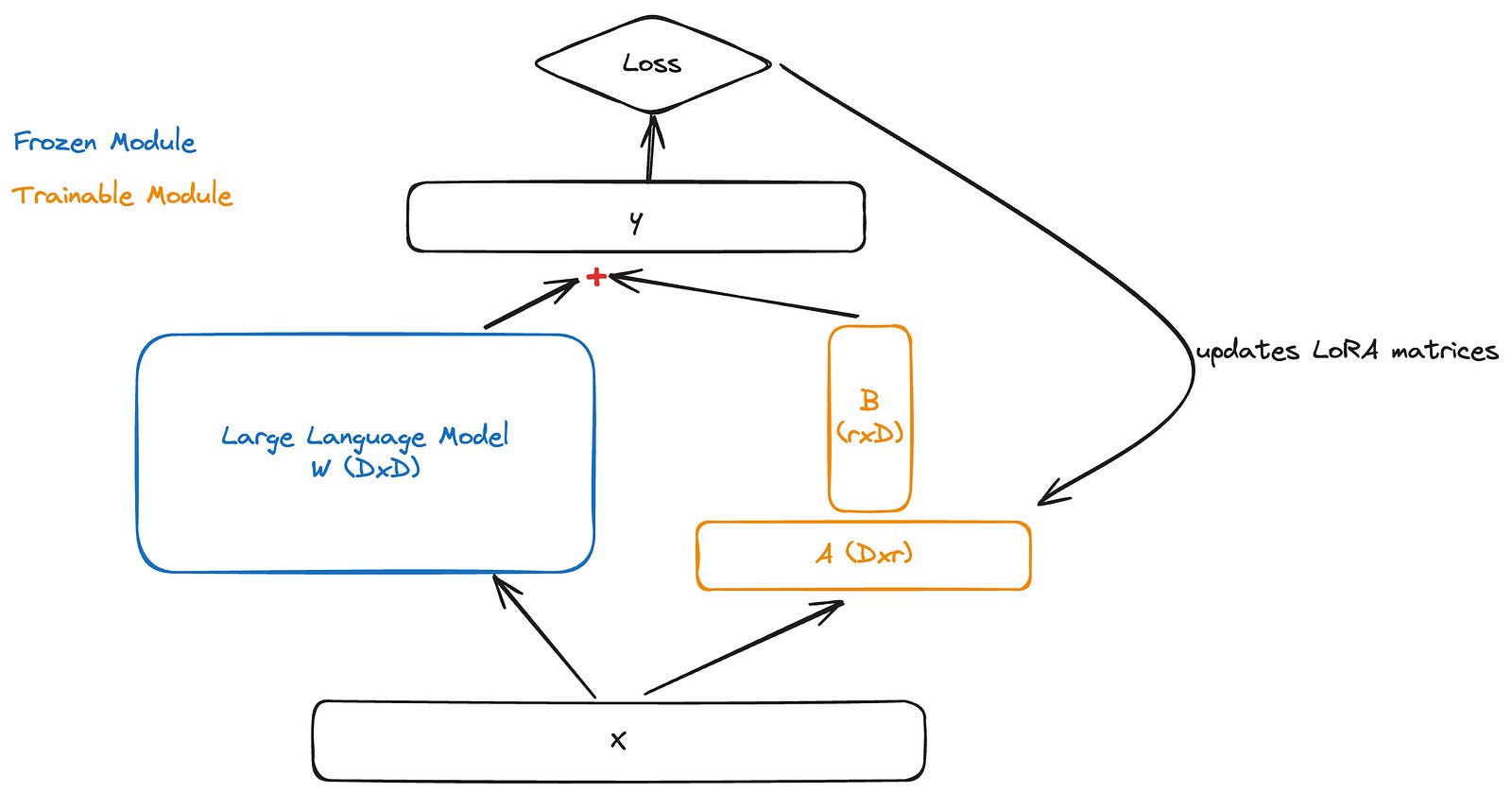
The main idea behind LoRA is to transform the adapter module into two low-rank matrices (which is why it’s called Low Rank Adaptation), denoted as A and B.
Let’s assume our frozen weights are represented by W0 with the shape D,D. Matrix A should have the shape D,r, and matrix B should have the shape r,D. So, when we multiply AB, we get the same shape as W0. The ‘r’ is supposed to be much smaller than ‘D’, which explains the term “low rank.”
Matrix A is initialized with random Gaussian values, while matrix B starts with zeros. Through back-propagation, we only update these two matrices.
So, the equation translates to:
y = W0x + ∆W x = W0x + ABxNow, when we back-propagate, we end up with:
dy/dx = W0 + ABBut since we only fine-tune the BA layers, W0 remains frozen. Therefore, we end up with far fewer gradients to store and update.
One question arises: by adding two new matrices, wouldn’t this slow down inference?
Since the shapes of the matrices are (D,r) and (r,D), when performing matrix multiplication, it results in a (D,D) shape. This can then be added element-wise to the W0 matrix. This means we have the same number of parameters as the original model, so there’s no increase in inference latency this is referred to as adapter merging.
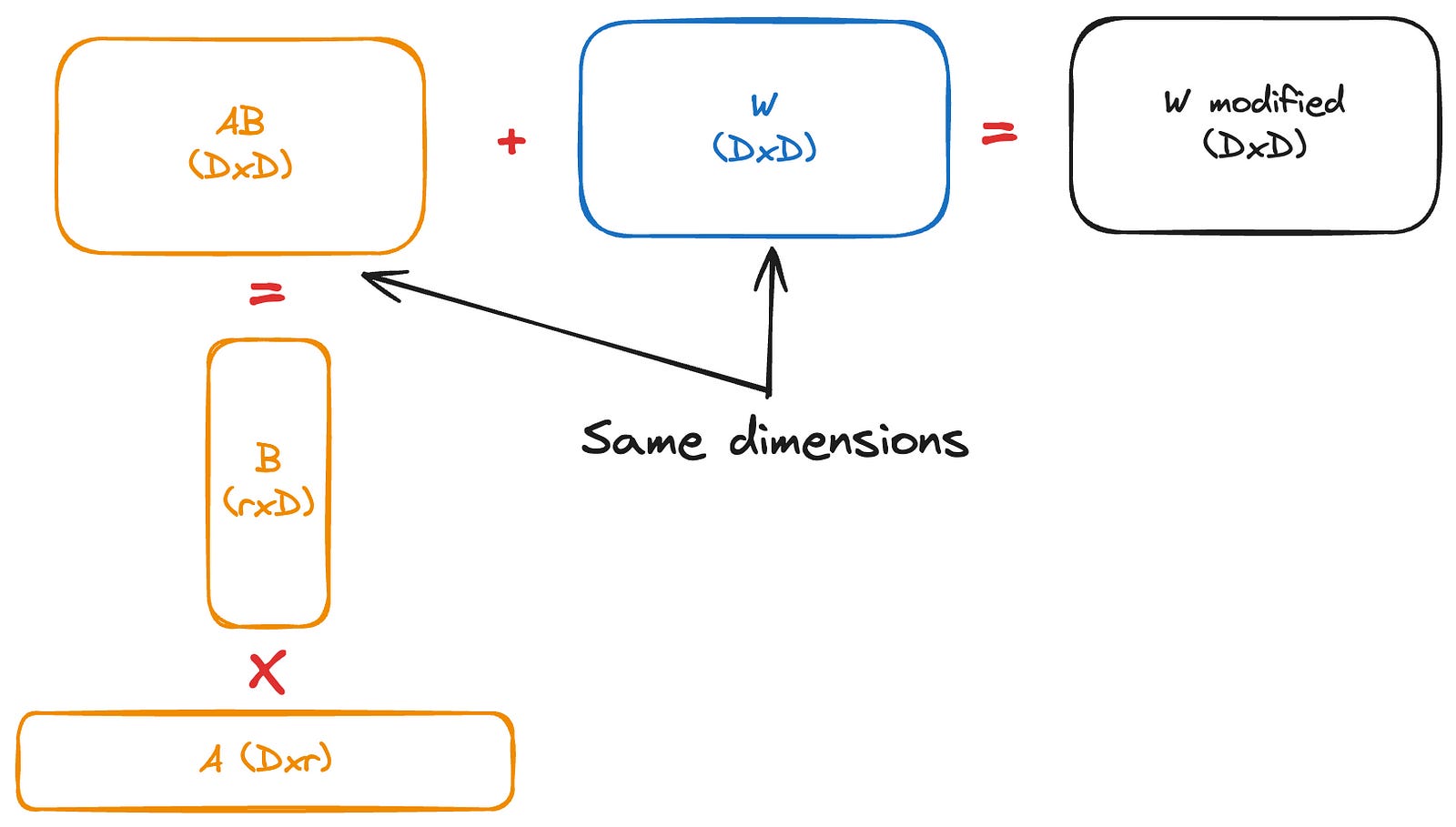
We can revert back to the original model by subtracting AB from the fine-tuned model weights.
The LoRA method suggests that eventually the resulting weights become similar to those obtained through fine-tuning (after increasing r ). DoRA proposes analyses of the resulting weights to inspect this assumption and introduces ways to improve it.
LoRA’s Magnitude And Direction Analysis
DoRA proposes restructuring the weights matrix into two components: magnitude and direction. It compares these components in fine-tuned and LoRA-tuned models.
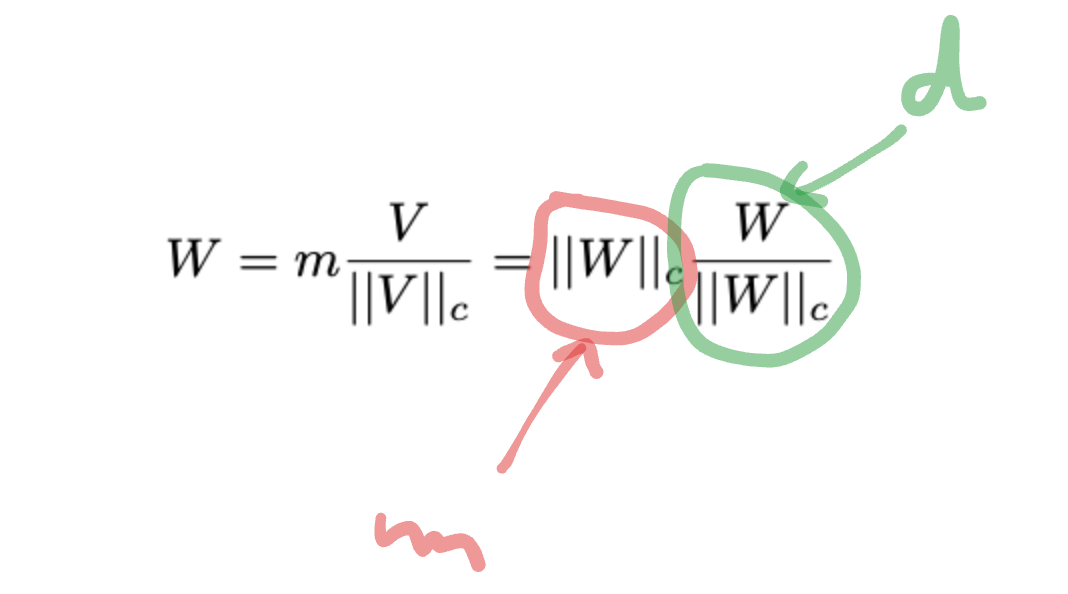
The decomposition of W into D,D can be formulated as: W = m V/ ||V ||c = ||W||c W /||W||c , where m is a 1,D magnitude vector, V is a D,D directional matrix, and ∣∣⋅∣∣c represents the vector-wise norm of a matrix across each column.
This decomposition ensures that each column of V/∣∣V∣∣c remains a unit vector, and the corresponding scalar in m defines the magnitude of each vector.
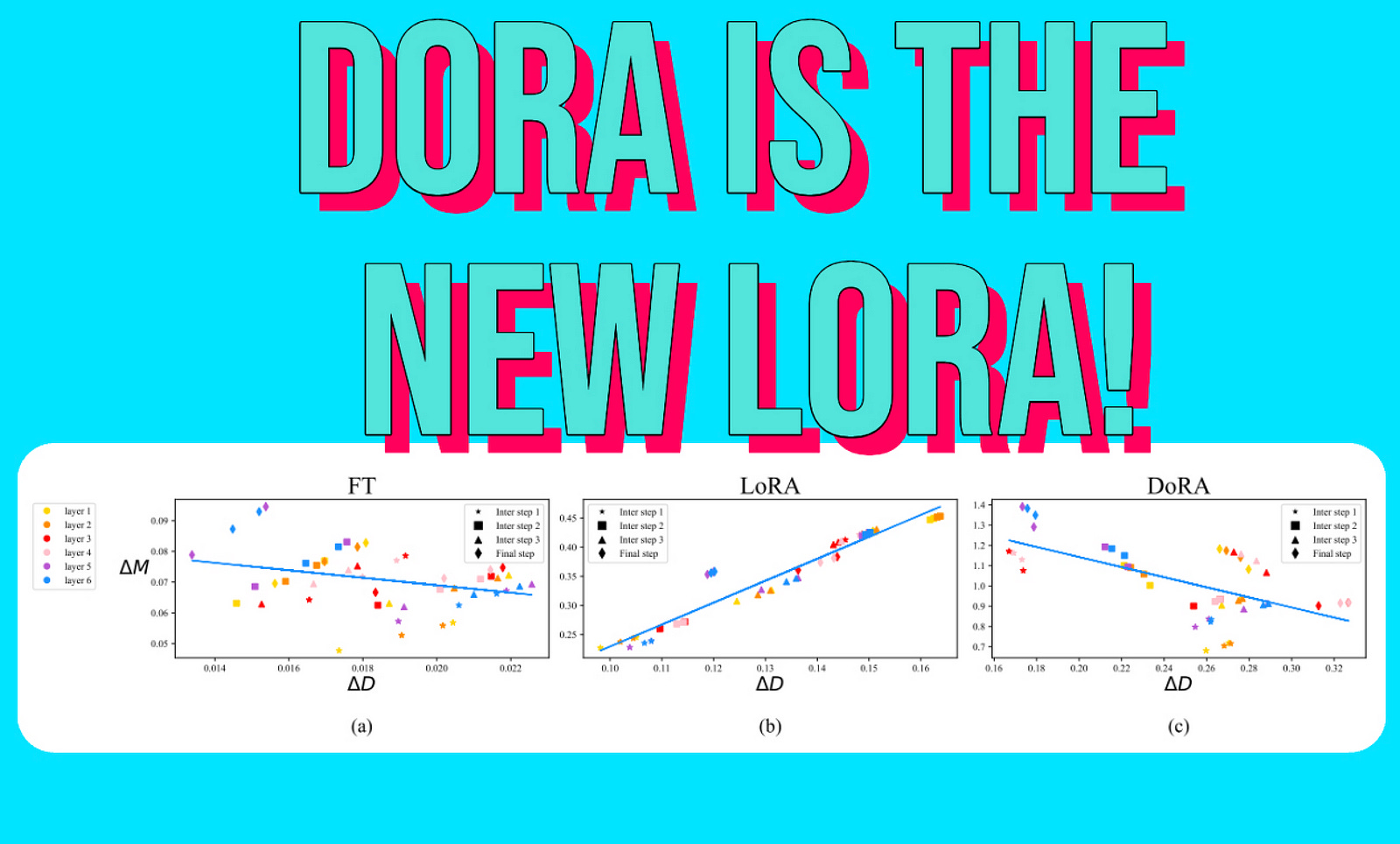
Now for the analysis, they use the BART VL model, both fine-tuned and LoRA-tuned, and measure the variation of the magnitude and direction at different timestamps t during training.
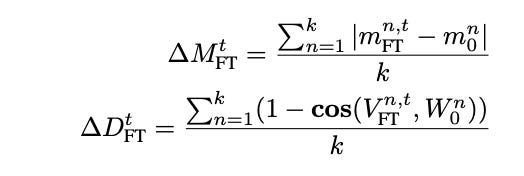
∆Mt FT is the average of the differences in magnitude scalars between the fine-tuned and pretrained model. We add up the differences between the nth scalar scalar in both vectors until we reach K.
∆Dt FT is also the average difference between the direction matrices for the fine-tuned and pretrained model. We sum the 1−cosine similarity between the vectors VFTn,t and W0n where n represents the nth column in the original matrices VFT and W0.
The same equations are applied to the LoRA weights
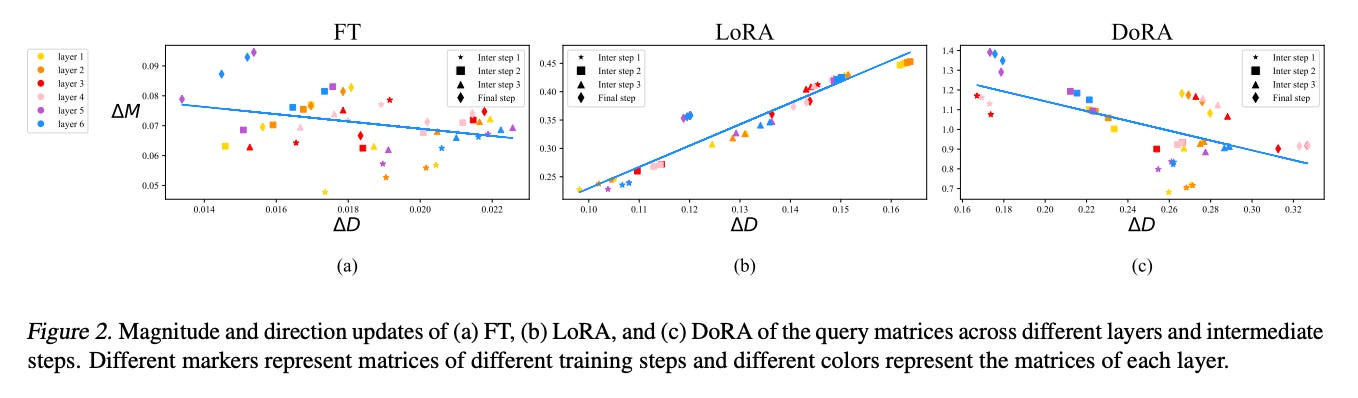
From graphs (a) and (b), we can observe that LoRA’s magnitude and direction variations are almost always proportional at different timestamps, forming a positive slope compared to the fine-tuned one. We can also see that the fine-tuned version has high variance (the dots are scattered across the graph), whereas LoRA has very low variance (the dots are close to the line).
It appears that LoRA is learning the same thing at multiple timestamps compared to the fine-tuned version, which exhibits much more nuanced and varied patterns across timestamps.
This suggests that fine-tuning helps to learn different patterns in the data and subtle changes, whereas LoRA seems invariant to these changes.
These limitations might stem from the fact that LoRA is unable to differentiate and adjust magnitude and direction separately.
From LoRA to DoRA
DoRA’s idea is to first decompose the pretrained weights into the two components we mentioned above: magnitude and direction, and then fine-tune them. The direction matrix is then further decomposed with the LoRA technique.
DoRA technique revolves around two main ideas.
The first is to restrict the LoRA technique to focus solely on the direction.
The second idea is to stabilize the optimization through weight decomposition.
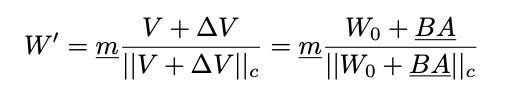
We end up with the following equation where m and BA are trainable.
DoRA adds a little bit more weights than LoRA. This is because of the m vector but also the normalizing denominator ||W0 + BA||c. However, during training, they treat it as a constant and don’t calculate gradients for it.
Now, when we analyze the graph above, we see that both the fine-tuned model (a) and DoRA (c) show similar behavior in terms of changes in magnitude and direction, where there is an inverse relationship between them.
Results
For evaluating this technique, the authors create a training dataset that combination of all the 8 tasks. Evaluations are conducted on tasks form individual datasets, following this setup.
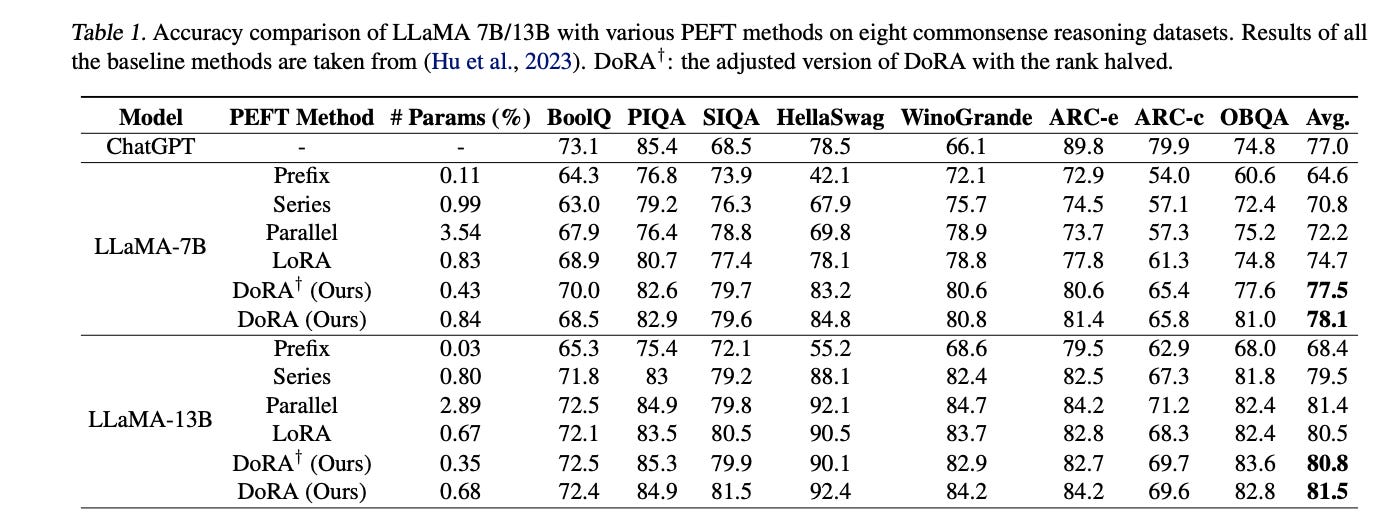
From the results we can see that DoRA outperforms LoRA in most of common sense reasoning datasets even with half the rank.
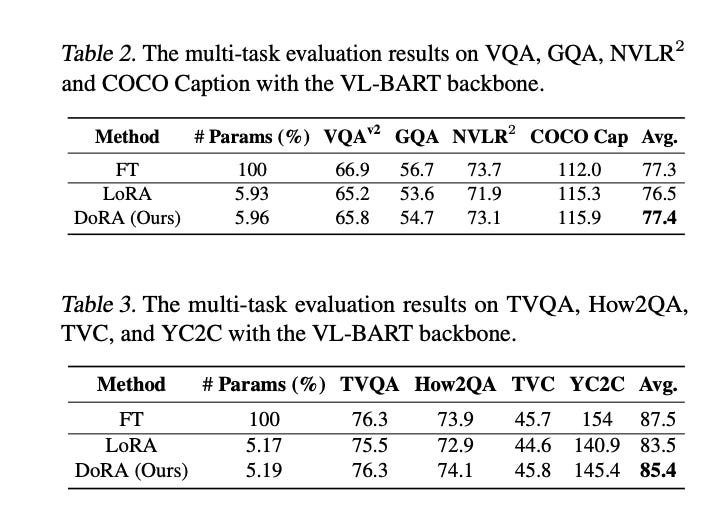
We can also say the same for tasks that involve text-image/video understanding.
We can notice that DoRA has slightly more parameters, this is due to the trainable vector m that represents the magnitude.
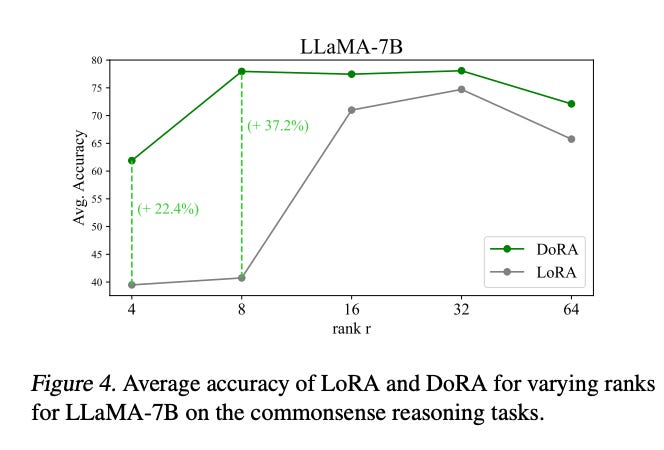
We also notice that regardless of the rank, the DoRA method is robust and will outperform LoRA. We observe that the greatest improvement occurs when we have smaller ranks. This is advantageous because we can achieve better performance while using smaller matrices, resulting in faster tuning.
Takeaways
LoRA is a method to fine-tune your LLM without needing to train all of the weight parameters. It utilizes two low-rank matrices to achieve this without adding extra inference latency.
When decomposing weights into magnitude and direction, we notice that LoRA’s weight updates do not match the updates from full fine-tuning due to coupling between the magnitude and directions.
DoRA proposes to separate the magnitude and direction, apply weight normalization, and use the LoRA technique on the direction matrix. This results in similar updates to the full fine-tuning version.
DoRA outperforms LoRA in common sense reasoning and also in understanding image/video to text. It is also robust to changes in rank; in fact, we observe the biggest increase in performance when the rank is low.
References
https://arxiv.org/pdf/2402.09353, DoRA paper.
https://arxiv.org/abs/2106.09685, LoRA paper.
Feel free to like, follow, and comment if you enjoyed the article!
Stay In touch by connecting via LinkedIn Aziz Belaweid or GitHub.