

Is Step Back Prompting The Best Prompting Strategy?
Is Step Back Prompting The Best Prompting Strategy?
Despite the proficiency of LLMs in conversations and information retrieval, they still struggle with multi-step reasoning tasks.

o address this issue, various prompting strategies have emerged to aid LLMs.

One prominent technique is Few-Shot Prompting, wherein examples illustrating how to solve such tasks are provided. Another effective method is Chain-of-Thought prompting, which involves adding “Let’s think step by step” to the prompt. Additionally, the TDB strategy prefaces the prompt with “Take a deep breath and work on this problem step by step.”
These prompting techniques collectively enhance the LLM’s performance by encouraging it to produce more tokens and avoid jumping directly to results, thereby improving its reasoning abilities. Recently, the Google DeepMind team introduced a new prompting strategy called “Step Back Prompting.”
Step Back Prompting
The motivation for this new prompting strategy stems from the observation that many tasks contain a lot of details, making it hard for the model to retrieve important facts to provide a proper answer.
What happens to the pressure, P, of an ideal gas if the temperature is increased by a factor of 2 and the volume is increased by a factor of 8 ?
Is an example of a question that can be answered if we could retrieve the relevant formula is provided. So, the idea of step-back prompting is to perform two steps:
Abstraction: Prompt the LLM about higher-level concepts and abstractions related to the question.
Reasoning: Using the question and the generated abstractions or high-level concepts, reason and provide the answer.
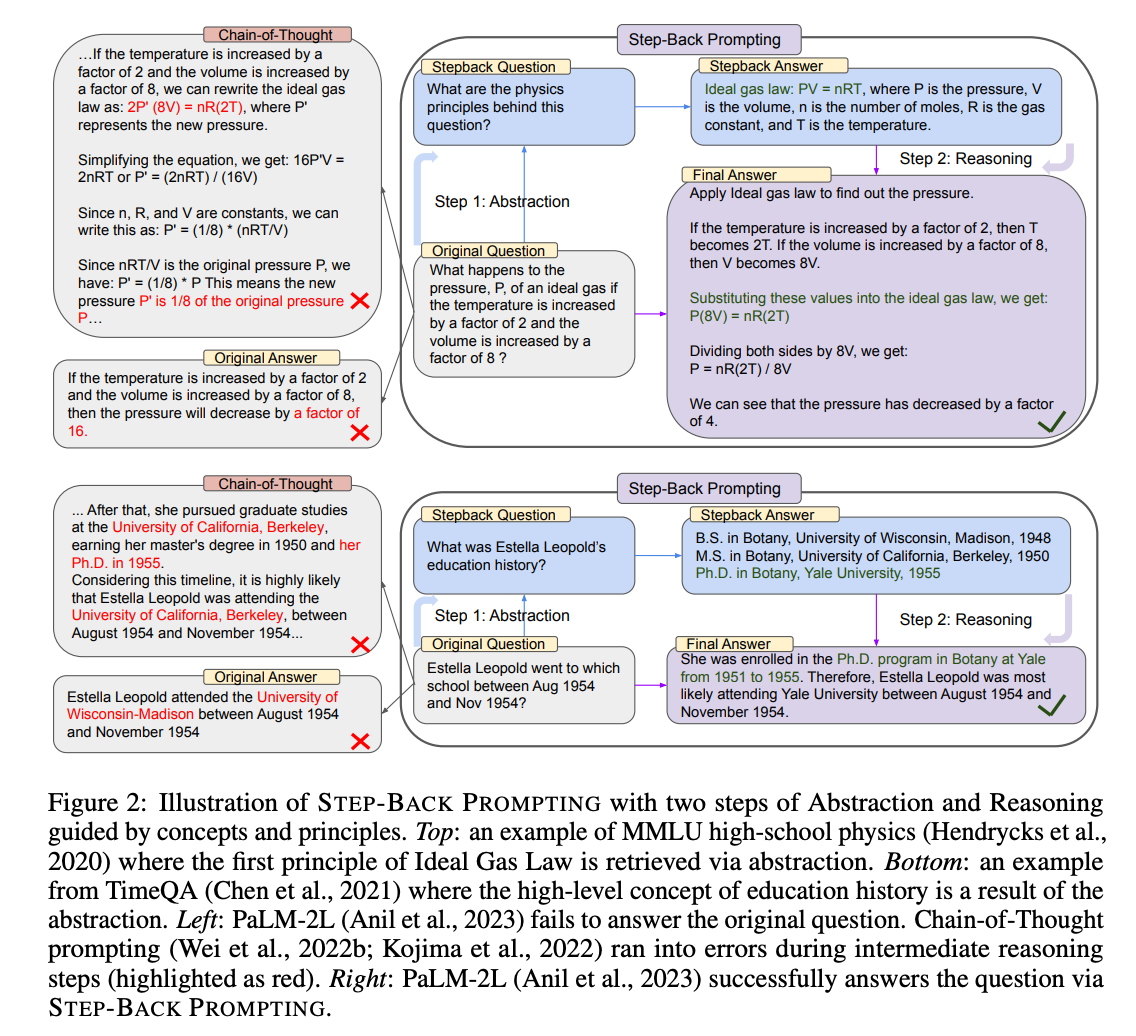
From the examples above, we can see how step-back prompting helps the model extract more general principles and then use them to answer specific questions.
Evaluation Datasets
To evaluate this approach, the team chose the following datasets:
MMLU Physics: Contains high school level questions of physics that require some knowledge and deep reasoning.
MMLU Chemistry: Contains high school level questions of chemistry that require some knowledge and deep reasoning.
TimeQA: Contains complex questions that require time reasoning and knowledge.
SituatedQA: Open QA datasets that requires reasoning over temporal and geographical context.
MuSiQue: A hard multihop reasoning dataset created via composable pairs of single-hop questions.
StrategyQA: Open-domain questions that demands some strategy to solve.
Models and Methods
To compare this approach against other approaches, the models used were PaLM-2L and GPT-4.
As for the methods, they experimented with out-of-the-box vanilla models with no prompting techniques, 1-shot examples, Chain-of-Thought with 1-shot examples, “Take a deep breath” prompt, and Retrieval Augmented Generation.
To compare the models, the PaLM2-L model was used with few-shot prompting to identify equivalence between target answers and the model predictions.
Using PaLM2-L to compare models might not be the best way to evaluate because it could be biased toward its responses compared to GPT-4’s responses.
The prompt they used is shown in the following table.

Step Back Prompting Results
The results of Step Back Prompting on the multiple datasets are as follows:
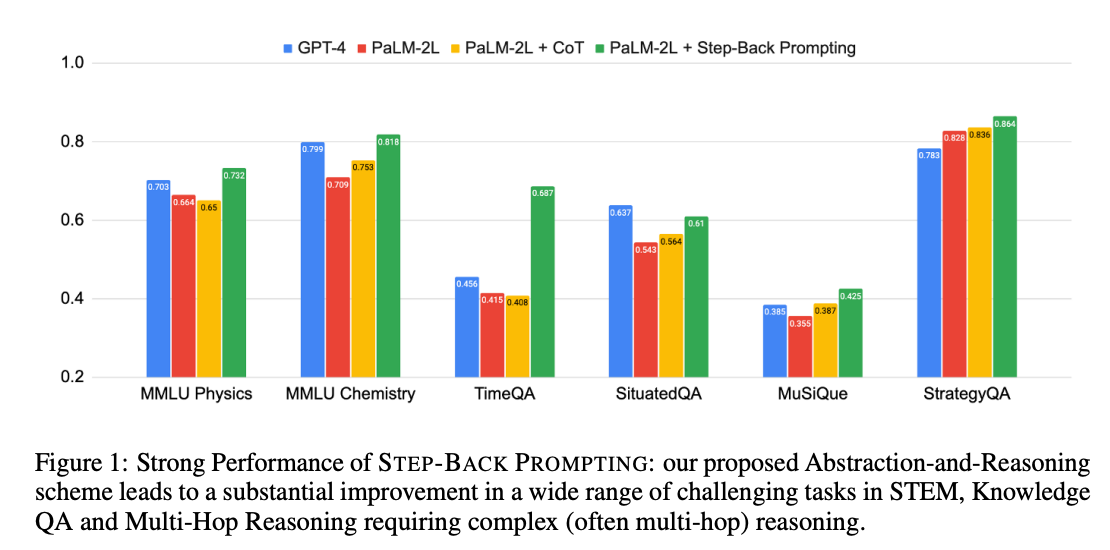
Step Back Prompting outperforms all other different prompting techniques and performs better than GPT-4, except on the SituatedQA dataset. There are also some interesting results that the authors have reached.
Having more examples doesn’t necessarily mean better performance; when we add more examples in the prompt, it doesn’t necessarily improve performance, as shown in two different datasets.
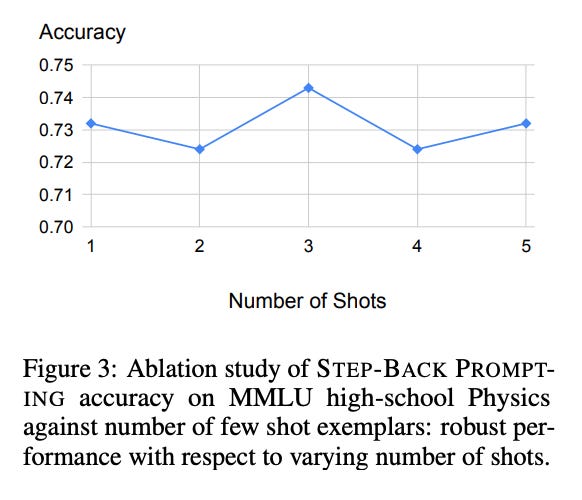
Same results are observed on TimeQA.

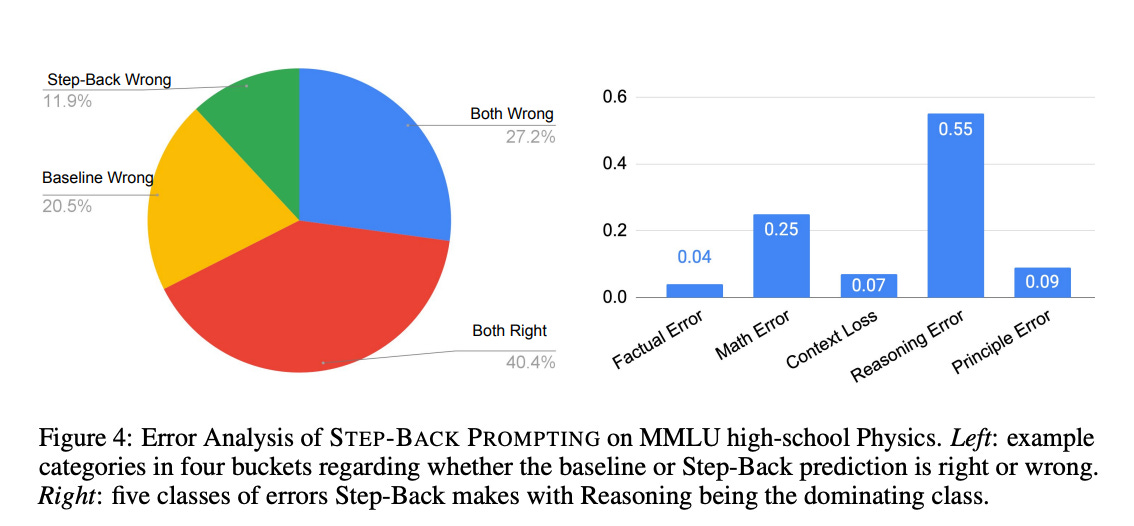
Most of the errors stem from the reasoning step, in which the model utilizes the provided information to generate a final answer. This indicates that even with abstraction and first principles, this step remains complex and requires multiple rounds of reasoning.
Conclusion and Takeaways
Step Back Prompting is a technique that prompts the model to consider abstractions and first principles before answering a question. It outperforms other prompting techniques, such as Chain of Thought and Few Shot Prompting.
However, it still doesn’t fully address prompting in general, as the reasoning step is very complex. Even with the aid of Step Back Prompting, obtaining the correct answer remains a challenge.
Additionally, I would argue that this method of prompting might not work in all cases. For example, some questions require direct knowledge, or they are inquiries about first principles themselves, eliminating the need to step back.
Feel free to clap, follow, and comment if you enjoyed the article!
Stay In touch by connecting via LinkedIn Aziz Belaweid or GitHub.