


Chameleon, Meta's Mixed-Modal Foundation Model
Recently, Meta released a new family of mixed-modal foundation models.

Unlike previous models, which modeled each modality separately and then combined them by relying on different encoders and decoders, the Chameleon family of models uses one architecture to model both modalities.
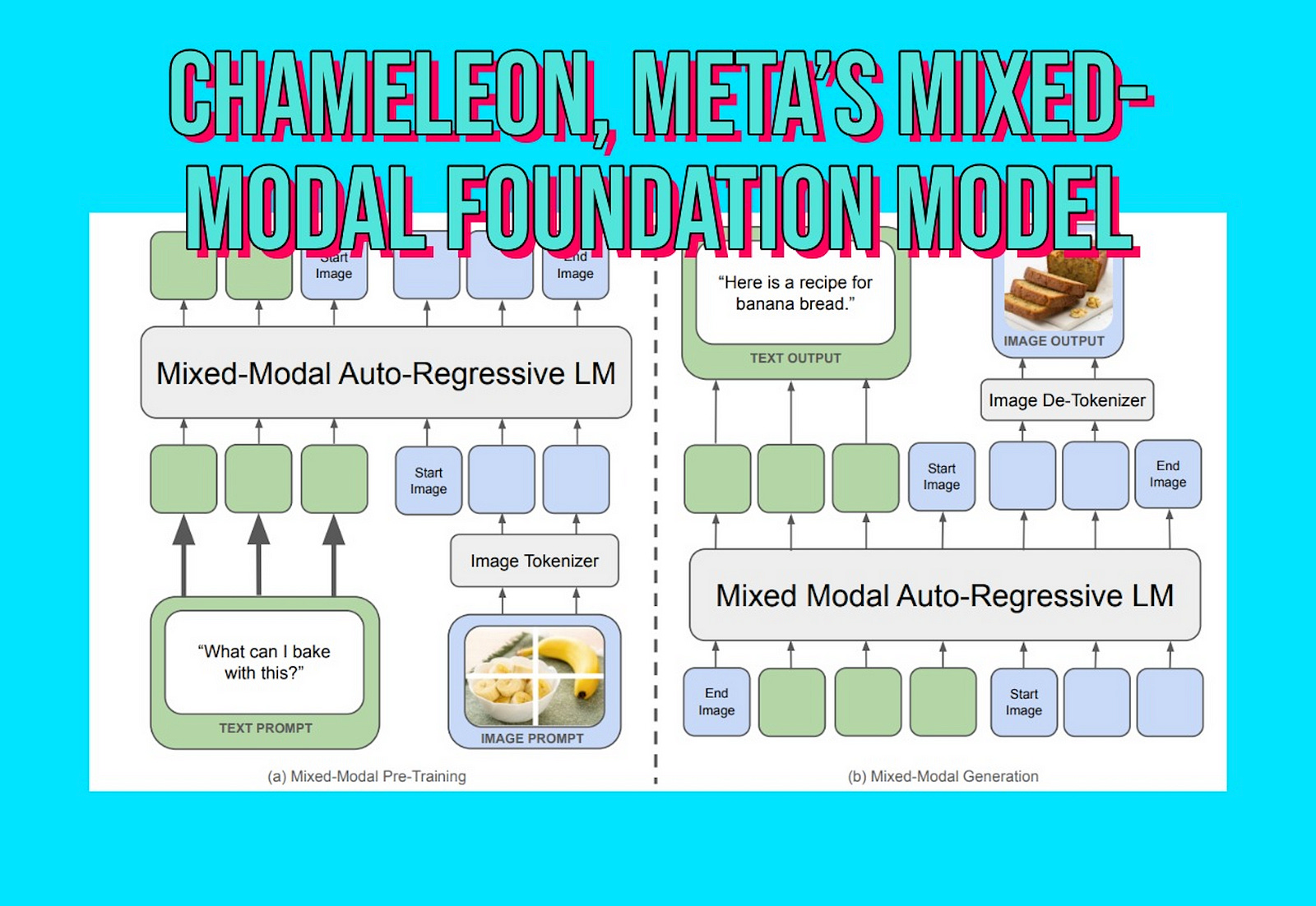
In simpler terms, if you wanted to create a model that understands both images and text, previous approaches combined two different models: one that represents images in an embedding space and one that represents text in a different embedding space, and then trained them jointly.
What Chameleon proposes is to create a single model that represents both modalities in one unified embedding space.
Representing different modalities in the same space can be challenging due to their different natures. Text is discrete, as it can be divided into a number of words or tokens, whereas images are continuous.
To address this, Meta’s team proposes using an image tokenizer. The job of this tokenizer is to transform an image into a discrete set of tokens.
These tokens, combined with text tokens, are fed into the same transformer architecture. This fusion allows the model to reason and generate across modalities easily.
As we will see later, this approach comes with its downsides, including issues with training stability and scaling.

The figure above provides an overview of what the paper describes: a single uniform model generating interleaved modalities but using two different tokenizers.
Training Chameleon
Tokenization
Image Tokenizer: The team trained an image tokenizer based on the work of Gafni et al. It takes an image of size 512x512 and encodes it into 1024 discrete tokens from a set of 8192 image tokens. They also upsampled the number of images with faces during pretraining by 2x. A weakness of this model is that it cannot reconstruct images with text within them, making it less effective for OCR-related tasks.
Text Tokenizer: For the text tokenizer, the team trained a BPE tokenizer using a subset of the training data. The vocabulary size is 65,536, including the 8192 image tokens. The training was conducted using the SentencePiece library.
Pretraining data
Now that we have our tokenizers ready, we need to prepare the data and pretrain our model. The pretraining is divided into two stages.
Stage 1, which comprises 80% of the full pretraining, uses the following data mixture:
Text-only data, used to train LLaMa-2 and CodeLLaMa, consisting of 2.9 trillion tokens of text-only data.
Text-image data, a combination of publicly available data sources and licensed data. The images are resized and center-cropped to 512x512 to prepare for tokenization. This produces 1.5 trillion text-image tokens.
Text-image interleaved data is also gathered from publicly available data resulting in 400 billion tokens, same processing that we applied to images has been applied here. The data is created according to this paper.
Text-Image data is pairs of text and image, but text-image interleaved data can be text and images interleaving like the picture below.

In stage2, the weight of stage1 training data is lowered by 50% and the model is further pretrained on higher quality data with the same proportion of text image tokens.
A filtered subset from instruction tuning datasets is included in this stage.
Chameleon model architecture and training stability
Model Architecture
The Chameleon model architecture is the same as LLaMa-2. You can read about it in my previous articles here and here.
For normalization, they use RMSNorm, and for the activation function, they use SwiGLU, which I explain here. For position embeddings, they use rotary position embeddings, which you can read about here.
Diversion Causes and Solutions
When adding modalities, the LLaMa architecture begins to diverge in the mid to late stages of the training. Since the same model weights are used for both text and image modalities, they compete with each other by increasing their norms.
More specifically, because the softmax function has a translation invariance property (softmax(z) = softmax(z + c)), signals get squashed.
To mitigate this problem, layer normalization is applied to the input of the softmax vectors, which are the keys and queries. Additionally, the dropout layer was also removed.
These changes managed to stabilize Chameleon 7B, but when scaling further to 34B, the model still diverges. This is due to the growth of the feed-forward network. Since it uses SwiGlu activation with multiplication, this leads to the growth of values.
To solve this, the team proposes reordering the normalization and feed-forward blocks such that normalization comes afterward.

Both Chameleon 7B and 34B can be trained without divergence using normalization reordering and QK norm, but without dropout layers.
Optimization Parameters
AdamW optimizer with β1 set to 0.9 and β2 to 0.95, with an ϵ = 10−5. Linear warm-up of 4000 steps with an exponential decay schedule of the learning rate to 0. Additionally, we apply a weight decay of 0.1 and global gradient clipping at a threshold of 1.0.
Even though QK norm solves the inner softmax problem within the transformer, it doesn’t help with the logit shift in the final softmax operation. Z-loss regularization is applied to fix this by adding 10−5 log2 Z to the loss function with Z being
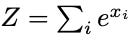
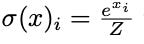
The following table summarizes all the training hyperparameters and differences with LLaMa models.

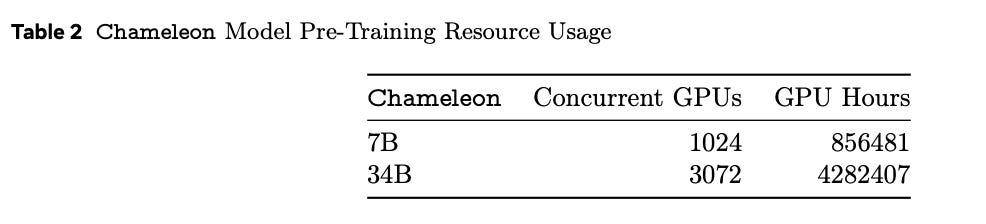
Pretraining Hardware
Models were trained on Meta’s reseach super cluster, NVIDIA A100 GPUs with 80GB of memory.
Inference
The team constructed an inference pipeline given the constraints at hand. When generating, tokens are checked one by one for modality to determine which tokenizer to use for detokenization.
In case we want to generate only one specific modality, masking is applied to mask out the other modality.
In both streaming mode and large chunk generation, checking the modality for the tokens is necessary. However, masking tokens does help expedite the process as there are fewer tokens to evaluate.
Aligning Chameleon
Data for Supervized Finetuning
To align the models the team used a variety of high quality datasets.
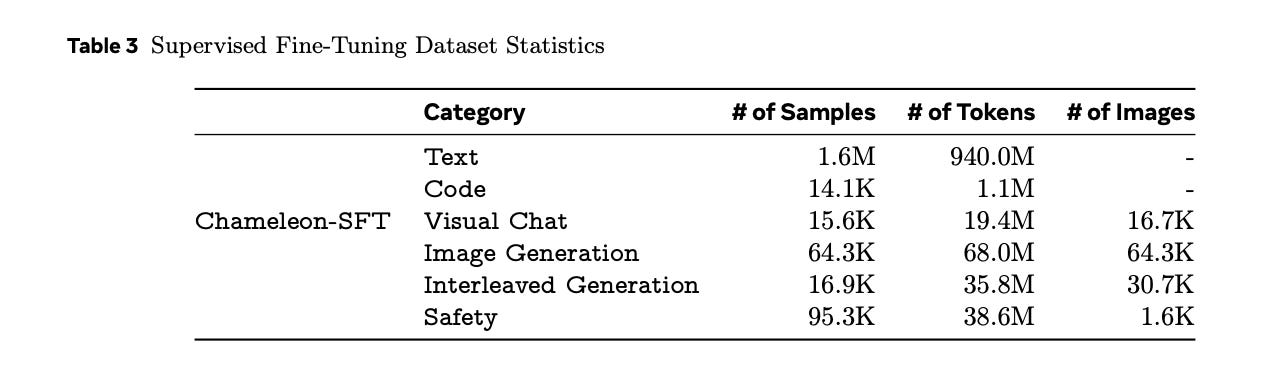
The Text SFT dataset from LLaMa-2 was used, along with CodeSFT from CodeLLaMa. Image Generation SFT data was created using an aesthetic classifier, where 64K images rated more than 6 and close to 512x512 in aspect ratio were retained.
For Visual Chat, Image generation, and Interleaved data, third-party vendors were responsible for data collection and providing very high quality.
Meta’s team also included safety data, which consists of prompts designed to elicit harmful responses from the model. They matched these prompts with a refusal response, “I can’t help with that.” The data includes examples from LLaMa-2 training data, image generation prompts from Pick a Pic, as well as mixed-modal prompts collected internally.
Finetuning
Modality balancing is crucial during SFT because it teaches the model that both modalities are equally important; otherwise, the model might learn to prioritize one modality while neglecting the other.
Optimization, a cosine learning rate schedule is created with an initial learning rate of 1e-5 and a weight decay of 0.1. The batch size is set to 128 with sequences up to 4096 tokens.
A special token indicates the end of a prompt and the beginning of the answer. For each sequence, the team utilized as many pairs of prompts and answers as possible.
The model was trained in an autoregressive manner, but the prompt tokens’ loss is masked since we aim for the model to learn the answers. A dropout of 0.05 and Z-loss are applied. Padding was added to the images to ensure that all the information from the images is included.
Evaluation
Since Chameleon is a new model with multimodal capabilities, there are not many existing benchmarks that can evaluate its performance.
Prompts for evaluating Multi Modal models
Meta worked with third-party vendors to collect evaluation prompts. They asked annotators to write prompts about how they would expect a multimodal model to work in real-life scenarios.
For example, questions like “How to cook pasta?” or “How should I design the layout of my island? Show me some examples.” The prompts can be text-only or text with images, but the expected response should be multimodal.
Three random annotators were then asked to filter out prompts that were unclear or did not expect a mixed-modal response.
The final evaluation set contains 1,048 prompts: 441 (42.1%) are mixed-modal (i.e., containing both text and images), and the remaining 607 (57.9%) are text-only.
Augmenting Models with Vision
To compare Chameleon with other models, the team augments Gemini Pro and GPT-4V with vision. They instruct the models by calling their APIs and adding this phrase at the end of the prompt: “If the question requires an image to be generated, then generate an image caption instead and enclose the caption in a pair of ⟨caption⟩ ⟨/caption⟩ tags.”
OpenAI DALL-E 3 is then used to generate images conditioned on these captions and replace the captions in the original responses with those generated images.

Absolute and Relative Evaluation
Two types of evaluations were conducted on the prompts gathered.
Absolute Evaluation means annotators judge responses from models separately by choosing if the model’s response fully fulfills, partially fulfills, or does not fulfill the task described in the prompt.
Relative Evaluation means annotators are shown two responses at the same time from two different models, and they choose which response was better or if they are the same.

As we can see from the figures above, Chameleon wins both absolute and relative evaluations according to the annotators. Annotators agree that Chameleon fully fulfills the task needed more than any other model. They also prefer Chameleon’s responses over any other model in most cases.
I wouldn’t take these results as comparing apples to apples, as the other models aren’t designed to generate images but have been augmented with an image generation model.
I would also say that some annotator bias exists, since the same third-party vendors annotated the data for the SFT of Chameleon and are also the ones who created evaluation prompts. It’s expected to prefer Chameleon’s responses over the others if you wrote the data yourself.
Benchmark Evaluation
The team conducted further evaluations on existing benchmarks to see if the presence of both modalities help or hurt model’s performance.
Text only evaluation

From the table above, we can see that Chameleon generally outperforms LLaMa-2 and is competitive with Mistral 8x7B. The team attributes these results to more epochs over the training data, including code data, which improves reasoning. Finally, due to the higher quality of data in stage 2, which represents 20% of the training process.
There was no mention, however, of the effect of the image modality and its impact on text-only results. We can at least say that the model didn’t regress on text-only tasks by adding the image modality.
Image to text evaluation

In general, Chameleon is competitive on both image captioning and VQA tasks with much bigger models (34B vs 80B), while needing much fewer shot examples. Flamingo and IDEFICS were tested with 32 shot examples, as opposed to only 2 for Chameleon.
However, Chameleon performs worse than GPT-4V and Gemini on VQAv2, potentially because they were fine-tuned on better proprietary data.
Chameleon Conclusion and Takeaways
Meta team introduced Chameleon in the 7B and 34B family of models, allowing seamless integration with different modalities by adopting an “all tokens” method and using text and image tokenizers.
Chameleon learns jointly over multiple modalities, introducing new challenges such as modality balance, stability, and scaling issues.
Applying QV normalization, removing dropout, using Z-loss, and reordering normalization are necessary for stable training of Chameleon 34B. Chameleon performs better than the other models in generating multimodal responses. However, this is not an apples-to-apples comparison, as the other models were prompted via API and augmented with a vision model. I also suspect annotator bias, as the same third-party vendors were responsible for creating the instruction tuning data and evaluation.
Adding the image modality doesn’t necessarily improve or hurt other modalities for Chameleon.
I wonder if Chameleon could be scaled further without having stability issues appearing again as we saw when scaling from 7B to 34B
Feel free to clap, follow, and comment if you enjoyed the article!
Stay In touch by connecting via LinkedIn Aziz Belaweid or GitHub.