
Dissecting OLMo, The Most Open Source LLM Paper!
Over the course of the last year, since the wave of LLMs started, many companies and organizations have released numerous models and papers.

However, many chose to vary their degree of openness regarding how you can create or replicate their paper’s results or models.
The reasons behind these choices are understandable, as there is a significant market and potential for business profit associated with these models. Pursuing a completely open-source approach would mean relinquishing a substantial advantage. Companies like OpenAI, Cohere, Google, and Anthropic profit from these models, so expecting full transparency is naive.
This approach hinders the general concept of advancing research in the AI field and makes it harder for other researchers to build on top of existing research if they don’t know precisely which data, models, parameters, and hardware were used.

To address this issue, the Allen Institute of AI released OLMo, a state-of-the-art, truly open language model, along with the entire framework behind it.
The key word in the previous sentence is “framework”. So what do they exactly mean by framework?
What is the OLMo Framework?
By “framework,” we mean everything — literally everything. Think about whatever you need to train and evaluate a model. You need data, data preparation pipelines, model architecture, hardware to train on, hyperparameters, schedulers, checkpoints, evaluation pipelines, and optimizers.
So, this is extremely exciting as it provides so many details on how you can train your own LLM. If you want to train your own LLM but don’t have an idea where to start, this paper is a very good starting point.
OLMo Model Architecture
The OLMo model has three variations: 1B, 7B, and 65B. At the time of writing, only the first two variations are available, and the 65B is still in training.

All three models adopt a decoder-only variation of the transformer and apply the following changes to the architecture. These changes are inspired by many other models and the results of some degree of openness of other LLMs.
No Biases: OLMo models do not have bias terms in their architecture, which leads to better training stability (following LLAMA and PALM).
No Parametric Layer Normalization: Results in faster results compared to other options (parametric layer norm and RMS norm). They also mention it is the safest; however, they do explain this further. I would assume this means training is more stable.
SwiGLU activation function: Used instead of the ReLU function (following LLAMA), the activation hidden size is increased to be a multiple of 128 to improve throughput.
Rotary Positional Embeddings: Replacing positional embeddings allows for wider context length (following LLAMA and PALM).
Vocabulary: A modified version of the BPE tokenizer is used. New tokens are added to mask out personally identifiable information (PII) and also to maximize throughput, ensuring it’s a multiple of 128. This results in a total of 50,304 tokens.

Pretraining Dataset Dolma
The dataset used for training is called Dolma. It is built by the Allen Institute of AI and is publicly released.
It comprises over 3 trillion tokens from 5 billion documents sourced from 7 datasets. The following table outlines how this dataset is created.
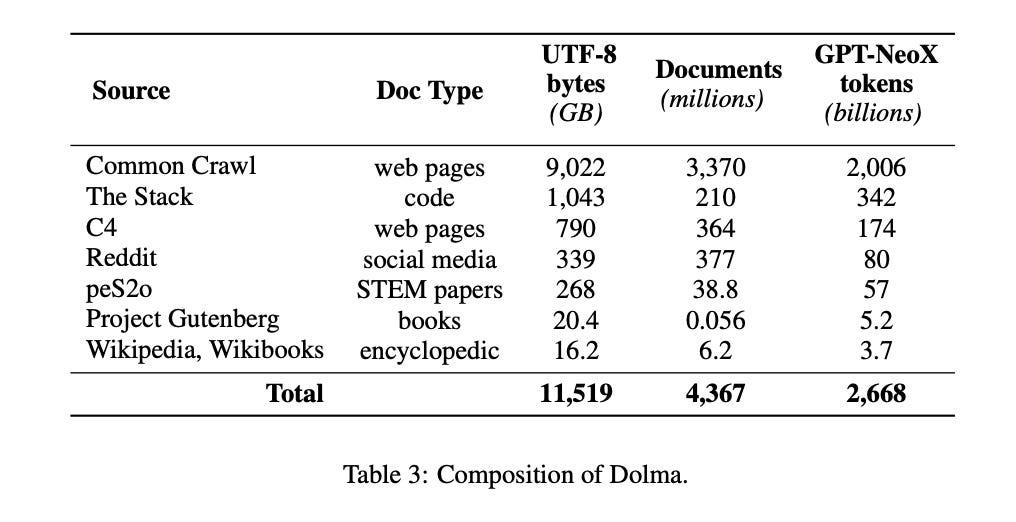
These datasets are commonly used in LLM pretraining; we can also observe them in Falcon’s dataset RedefinedWeb.
Many preprocessing steps are applied to these datasets to construct the final Dolma. These steps include: (1) language filtering, (2) quality filtering, (3) content filtering, (4) deduplication, (5) multi-source mixing, and (6) tokenization.
The OLMo paper doesn’t discuss much detail on the dataset. These details can be found in the Dolma paper, where the process is described with more information.
The team also open-sourced tools that can be used to curate and analyze datasets of this scale, such as the WIMBD tool.
Training OLMo
To train OLMo, we need to have a training pipeline set up. This includes a distributed training framework, GPU clusters, optimizer, and data.
Distributed Training Framework
To train OLMo, the team employed the ZeRO optimizer strategy with PyTorch’s FSDP framework, enabling the sharding of model weights and optimizer state across GPU clusters.
For enhanced throughput, they utilized mixed precision training through PyTorch’s AMP module. This approach allows certain operations, like the softmax operation, to be conducted in full precision for greater stability, while others are executed in half precision (bfloat16).
The sharded model weights and optimizer state remain in full precision on each GPU and are only cast to half precision when required.
Optimizer And Scheduler
The optimizer used is AdamW with the following parameters.
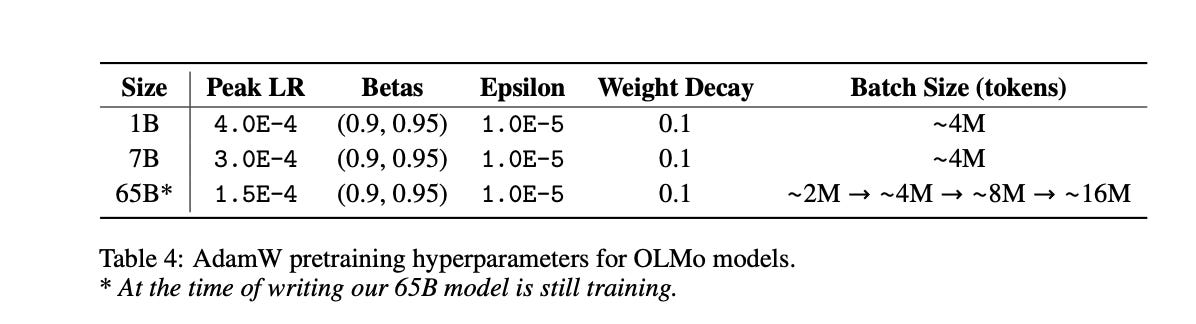
The learning rate is warmed up to 5000 steps and then decayed linearly. After the warm up period the gradients are clipped such as they do not exceed 1.0.
Data
A sample of 2T tokens from Dolma is used for training. Documents are concatenated to each other with a special EOS token in between. Each training instance is a chunk of 2048 tokens, and for every training run, these instances are presented in the same order.
Hardware
To ensure that the codebase can run successfully on both NVIDIA and AMD GPUs, yielding the same results, two clusters have been used.
LUMI: Provided by LUMI supercomputer, this cluster has 256 nodes, each node has 4x AMD MI250X GPUs with 128GB of memory5 and 800Gbps of interconnect.
MosaicML: Provided by MosaicML(Databricks), this cluster has 27 nodes, each node consists of 8x NVIDIA A100 GPUs with 40GB of memory and 800Gbps of interconnect.
Both runs on these different clusters result in the same performance after being trained on 2T tokens.
OLMo Evaluation
The Allen Institute of AI evaluates the models at two different stages: online and offline.
Online Evaluation It is run in-loop after every 1000 training steps (equivalent to 4B tokens). The goal behind this evaluation is to monitor the model’s performance and detect any problems in model training early on. This also helps in comparing and choosing model designs and hyperparameters.
Offline Evaluation is ran with model checkpoints to evaluate their performance with other models.
The evaluation focuses on 3 different things:
Downstream Evaluation: a set 8 tasks designed to evaluate commonsense reasoning. These tasks are arc_easy, arc_challenge, boolq, hella-swag, openbookqa, piqa, sciq, winogrande.
In all these datasets zero shot rank classification is used where multiple choice options are ranked by likelihood.

The results show that OLMo 7B is competitive with all other models on these 8 tasks.
Intrinsic Language Model Evaluation: The team used a subset of 11 sources from a total of 18 from Paloma.
Paloma is a perplexity benchmark with 585 different domains of text. These domain are drawn from 18 sources such as Reddit, C4, nytimes.com.
After going through a decontamination process also removing toxic text, this leave us with the subset of 11 sources.

The team used the Bits per byte metric to allow a fair comparison between models, as they have different vocabularies.
As we can see from the figure above, OLMo 7B competes well with other models.
Differences in performance across various datasets stem primarily from variations in training dataset distribution and different decisions in data preprocessing.
For instance, on RedefinedWeb, the Falcon model outperforms others likely because it was primarily trained on that dataset. OLMo performs notably well on C4, which constitutes 88.8% of its pretraining data.
Adaptation Evaluation: This evaluation focuses on OLMo’s capabilities after instruction finetuning and DPO(direct policy optimization) training.
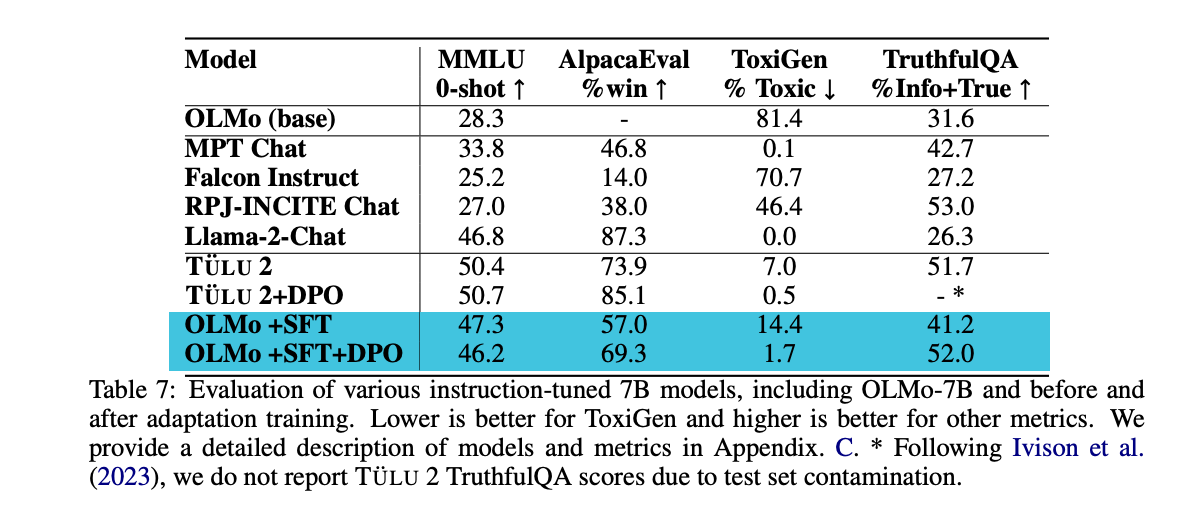
We see that after supervised fine-tuning (SFT) and DPO, OLMo’s performance across all datasets improved.
We observe that SFT greatly improved results on MMLU, and DPO gave an extra boost for AlpacaEval, ToxiGen, and TruthfulQA.
Tülu 2 out of the box performs well on many of the datasets. The authors speculate that this may be due to contamination of the test set.
Conclusion
The Allen Institute of AI provided us with a complete framework to train our own LLMs and gave us a tour of what happens behind the scenes. This includes the process for training LLMs as well as the code and data for pretraining and evaluation.
Resources
Evaluation: https://github.com/allenai/OLMo-Eval
Adaptation: https://github.com/allenai/open-instruct
Paloma Eval data: https://arxiv.org/html/2312.10523v1
WIMBD data analysis tool: https://github.com/allenai/wimbd
Follow and Comment if you like the article!
Stay In touch by connecting via LinkedIn Aziz Belaweid or GitHub.