


How To Create Automatic Music Playlists With RL?
Having the perfect music playlist is a dream most of us want. Whether you are on your journey to work, or in your car going to meet your friends you could just put this magic playlist and enjoy.


You don’t have to change between songs, no need to search for a specific song. This playlist just gets you…
In this article we’re going to discuss an approach on how you could create such marvellous playlist. This approach is created by research team at Spotify, it uses Reinforcement Learning to select best tracks depending on user preferences and also context of the tracks.
What is Music Playlist Personalization?
Personalization means making something more personal, adding to it your specific touch, something that is unique to you. This a broad concept and it’s applied everywhere now. We can even say that it has became a commodity that people expect.
In the context of music playlist, personalization means, “I want you to recommend tracks specific for me”. For example, a playlist that shows Rocks Songs can be very generic playlist.
For my dad this could mean Led Zepplin, Pink Floyd. For my mom it’s Queen, Eagles and Oasis. For my brother this mens Linkinpark, Radiohead and Nirvana.
Just as people are different in many ways, playlists should be different. Playlists are an experience to be savoured. They should not be a one size fits all kind of things.
For example, I in the morning would like to listen to high energy songs that I am already familiar with to get the day started, then I would listen to some rap in the afternoon and afterwards explore underground banjo singers in a forest somewhere.
How can we capture this diversity across so many users and also adapt with users as they grow in life and experience music differently?
Why The Current Methods Suck?
Current Methods relying on Collaborative Filtering and Sequence Modelling, make many assumption on what makes a track good or not.
These assumption they either come from music industry experience or from user interactions with the track. Some examples on these assumptions are, a track is good if a user liked it, replayed it, the track has a low skip rate, a track is similar to tracks that user liked before(cosine similarity).
All these assumptions work in general but it doesn’t feel like it completely matches or understands user preference. This is because, listening to music is an experience.
Repeating the same experience that I like before will not enjoyable anymore. More than that, the user’s behaviour and preferences change overtime. The user’s experience with music depends on countless factors that cannot be represented within an array of features.
Consider food for example, a user may like cheese, hates wine but he could enjoy wine with cheese. A user likes pancakes in the morning but maybe also after coming home drunk and he’s hungry. A user could hate vegetables at a certain but then rediscovers them.
A user can be in a exploitation mood where he wants to consume, things he is already familiar with like pasta or in an exploration mood where he wants to eat pineapple pizza.
Music is like food it’s an experience, it depends not only on the content quality, it depends on the user’s context, interactions with the track and the evolution of the “relationship” between both of them.
How Can Reinforcement Learning Fix That?
In this paper, the authors attempt to solve this using RL, let’s see how we can do that.
For the problem at hand which is automatic playlist creation, we first consider a catalog of millions of songs. We assume that we have representative features for each of these songs. These features can be genre, mood, beat-per-minute, number of plays,… the list goes on and on. We can also add the actual music embedding, if we require.
To reduce complexity, we can narrow down this catalogue from millions to hundred thousands of tracks, assuming that the user will choose for example a “Rock” or “Workout” playlist, then simple filtering based on genre or mood will suffice to reduce the number of candidate songs to choose from.
Now from the filtered pool, we need to select the best songs to formulate such a playlist with respect to the user.
Contrary to what Collaborative Filtering and Sequence Modelling do, they rely on information such as the user likes a track, or any other information as it’s a source of absolute truth, that’s unchangeable.
In Reinforcement Learning, we try to train a user behaviour model. This means this model will predict if a user will be satisfied with this track in the playlist. To do this we need to understand user listening patterns. For example “What do you usually listen to in the morning?, during your car ride? before sleep? during working hours?”.
To this end, we get all the information about the user such as user listening sessions, what tracks did the user complete/ skip, device type, what is the order of the tracks, time of day and so on.
Methodology And Training Loop
Now that we understand the problem and what we want to solve. let’s see the methodology and the RL lingo to solve it.
State: The current environment state, this is a set of features that represent, the current situation. Basically this is a point in time where a user is on the phone, listening to a track, in the morning.
Action: This is the next track to recommend to the user.
Reward: This is the result of choosing a track to listeners, this is a function that tells us if the user likes the track or not based on the current state.
Environment/World Model: This model is responsible for mimicking the user behaviour, after a track is recommended. It will produce a reward.
Policy: This is the model responsible for choosing the track, based on current state, and previous rewards.
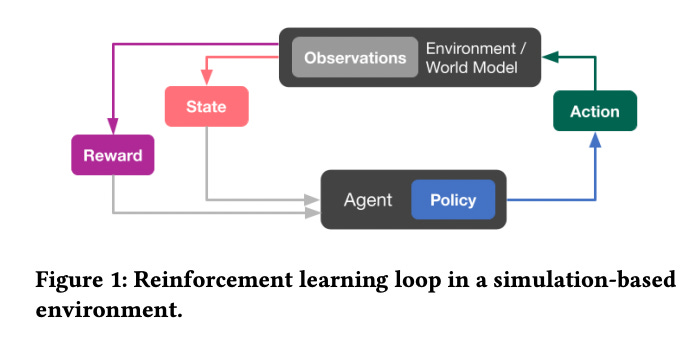
In action we start from an initial state (User is listening to track0), the Agent using the policy recommends a track, the track goes into the World Model which returns a new state and a reward(User listens to recommended track and either completes it to a certain extent or skips it). This reward provides feedback for the policy and using the new state a new track is recommended.
World/User Behaviour Model Design
Before such model is deployed online, it needs to be trained offline in a similar setup.
The world model takes as input, features about track pool, user state, features and current track information. It will start a session, keep track of recommend tracks to the user, tracks user responses to the tracks and ends the session.
It uses a user model to predict user’s response to a given track in a given state.
The user model should reflect real users’s behaviour as accurately as possible. It is a supervised classifier that is trained on user’s previous listening sessions data.
The model is optimized to predict three things:
If the user will complete the candidate track
If the user will skip the candidate track
If the user will listen for X amount of seconds to the candidate track
Two different versions of the user model are proposed:
Sequential version (SWM): Sequential version takes into account previous tracks. It’s a 3-layer model with (500, 200, 200) LSTM units. Takes also into consideration user and session features.
Non-sequential version (CWM): A series of dense layers where the the input are features that summarize the track and the user with no other information on the session itself (such as position of the track within the session, or user responses of previous tracks in the session).
There are trade-offs in choosing which model to use, CWM model is easier to use and faster to train the agent. However SWM is more accurate in predictions.
We notice that the user model can actually be trained by using existing data. It can then be a good baseline as an agent policy.
By using a greedy algorithm to rank the result of the CWM model on the candidate tracks, we now have a ready to use policy. This approach is referred to as CWM-GMPC(Greedy Model Predictive Control).
Action Head DQN Agent
Now that we have defined our user model. Let’s look at how we select the next action/track.
The DQN agent uses a deep neural network that assigns a score Q for every track. The track with the highest Q score gets recommended.
In this case, there are some limitations such as the track pool is dynamic and is changing overtime.
Also the overlap between different track pools is small since tracks will be groups by genres or moods. As it also depends on users that means you’ll have to maintain multiple agents per combination of pools-users which is a lot.
Therefore Action Head DQN Agent is introduced. It takes as input the current state and a list of actions. This means the Q network can be optimized independently from the set of available actions. Every environment is modeled as Contextual MDP.
Evaluation & Results
Experiments were conducted on both offline and online settings.
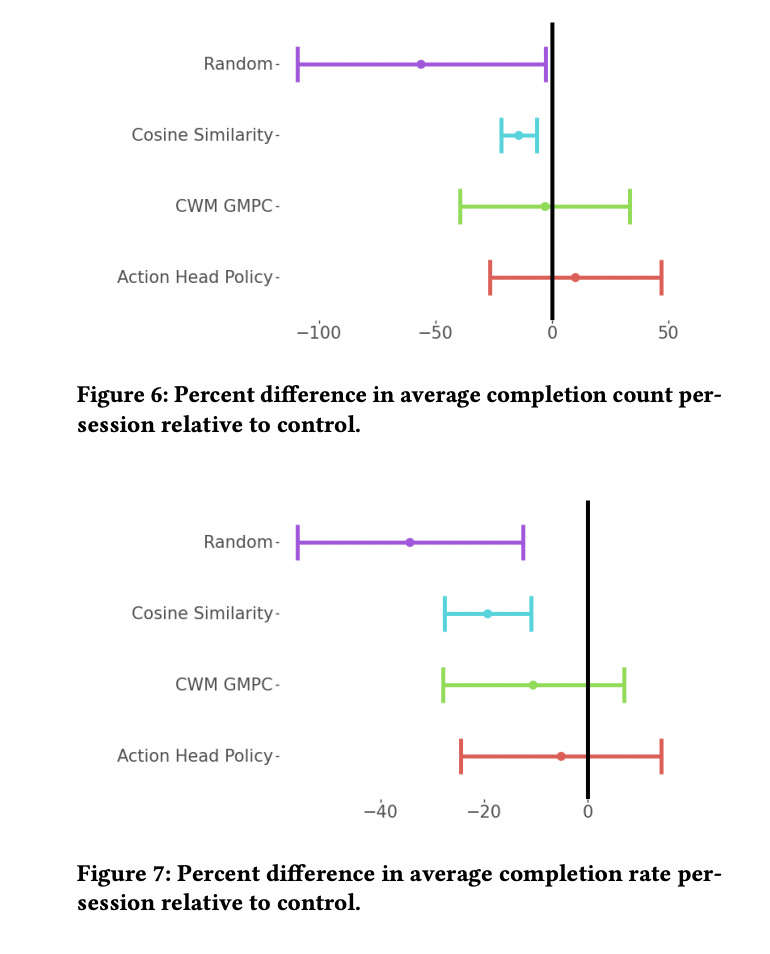

Resulting tables and figures show that both CWM-GMPC and Action Head Policy show promising performance and an increase in completion rate and count. Also they lead to a decrease in skip rate.
Paper link is here for more details.
I hope this article helped you in any way, if so Clap, Comment and Follow.
Stay In touch by connecting to us on LinkedIn Aziz Belaweid.