


Phi-3, your Pocket LLM!
Microsoft recently introduced Phi-3 family of models that is at the same time highly performant but also small enough to run on your phone without internet.


Up until now, all LLMs that we have seen are big in size and take up to gigabytes of GPU memory to run. Even after applying techniques like quantization, it would still not fit on your phone.
You can go for smaller models that could be able to run on your phone but no doubt that the performance would be worse.
Microsoft’s Phi-3 solves this problem and provides models that could “fit in your pocket” and still be good.
Let’s dive into the technical report.
The Phi-3 Family
Phi-3-mini: Decoder architecture with 4K context length, has 3.8B parameters trained on 3.3T tokens of data.
Phi-3-mini-128K: Same as Phi-3-mini but also uses LongRope technique to increase context length to 128K tokens.
Both Phi-3-mini models leverage same tokenizer as LLAMA2 with vocabulary size of 320641, this means you can directly adapt LLAMA2 packages to Phi-3.
The model uses 3072 hidden dimension, 32 heads and 32 layers. it was trained using bfloat16 for a total of 3.3T tokens.
Phi-3-small: Has 7B parameters leverages tiktoken tokenizer(better for multilingual purposes) with vocabulary size of f 100352 and has default context length 8K. It has 32 layers and a hidden size of 4096.
It leverages grouped query attention to minimize KV cache with 4 queries sharing 1 key. An additional 10% of multilingual data was used to train this model, for a total of 4.8T tokens
Phi-3-medium: 14B parameters using the same tokenizer and architecture of phi-3-mini, and trained on the same data for
slightly more epochs (4.8T tokens). The model has 40 heads and 40 layers, with embedding dimension 5120.
4-bit Quantized phi-3-mini runs natively on an iPhone with A16 Bionic chip, generating over 12 tokens per second.
It only occupies ≈ 1.8GB of memory.
What Makes Phi-3 so performant despite being small?
What’s different about Phi-3 is the way Microsoft creates the training data, after all the architecture of different models isn’t different from what we have seen before. The idea is to deviate from the scaling laws and to use high quality data to train small models.
They define high quality data by heavily filtering internet data and focusing on educational material as well as using LLM generated data. They train the Phi family of models in two sequential and disjoint stages.
The first stage focuses on web data that teaches the model general knowledge and language.
The second stage focuses on logical reasoning using heavily filtered web data and LLM generated content.
An example of data that gets filtered is the result of a football game on a given day, even though this might be useful for big models, they say it’s better to filter this information and leave capacity for the model to learn reasoning. They define this as Data Optimal Regime.

In the figure above, they train both Phi family and Llama2 family on the same data, according to the Data Optimal Regime. Notice how much smaller models perform better on MMLU than bigger models.
My interpretation is that bigger models need to be trained for longer because they have more parameters.
One question mark is that Phi’s bigger model Phi-3-small with 7B parameters is close to Llama-2 smallest model, I would expect they had similar performance or at least close which doesn’t happen here.
Post-training: After pretraining the models, they also do instruction finetuning and preference training with DPO improving the model’s chat capabilities and safety.
Benchmarks, Safety and Weaknesses
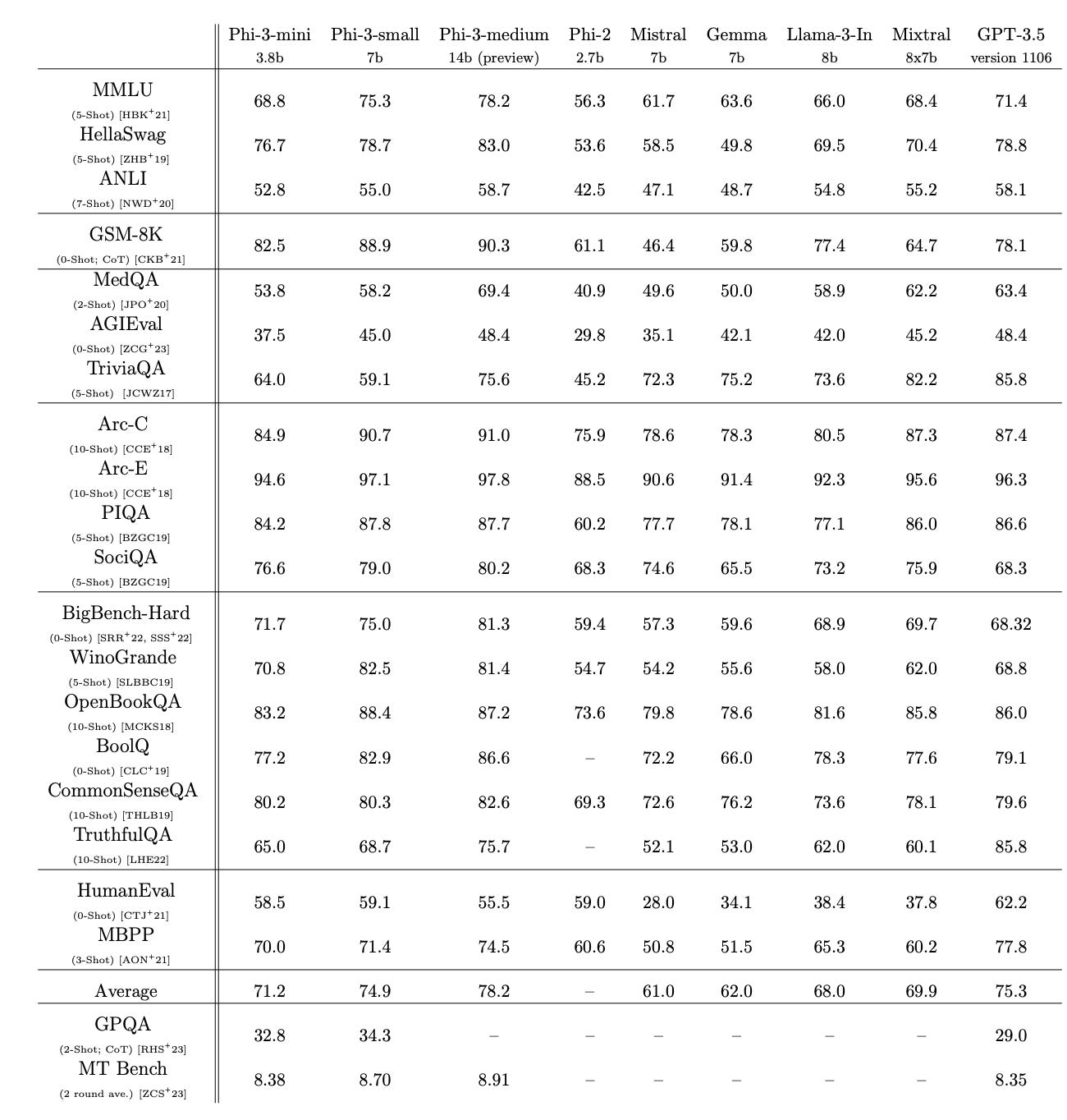
To conduct evaluations on multiple benchmarks, the team used the same pipeline with model at tempreture 0. The prompts used and the number of shots varies from task to task which raises a question mark here. They mention that the evaluation pipeline is part of Microsoft’s internal tool for evaluating LLMs.
They compare the new family of models to Phi-2, Mistral, Gemma, Llama-3 and GPT-3.5.
We can see that Phi-3 mini outperforms many models on many benchmarks except for triviaQA which requires more factual knowledge.
A possible solution to this is to add a search engine or information retrieval pipeline.
We also see that Phi-3 medium which has 14B parameters performs the same as half size models on triviaQA, this tells us how much the data used focuses on reasoning and not factual knowledge.
A notable weakness to this small model as well is that it’s not multilingual. Exploring this direction is worth researching for small models.
Technical Report Link: https://arxiv.org/pdf/2404.14219.pdf
Feel free to clap, follow, and comment if you enjoyed the article!
Stay In touch by connecting via LinkedIn Aziz Belaweid or GitHub.