


Reinforcement Learning With AI Feedback Explained!
The problem is RLHF is that it does not scale. To do RLHF you need human labelers to label the generations by your SFT(supervised finetuned) model.

Aside from the effort needed to build the interface that the users are going to build, if you want to apply RLHF to a specific niche domain you would need many human labelers expert in that domain to provide that annotations needed.
For example if you need to build an LLM specialized in coding you would need a number of programmers to rate the generations of your SFT LLM. This would be both time and money consuming.
Time because humans are slow compared to computers, money because programmers will charge you higher for their availability and expertise.
Even though RLHF is necessary in augmenting LLMs with human preference and taking their generations from good to great, they represent a slow expensive bottleneck in creating LLMs.

Using AI For Feedback
Instead of relying on humans to rate LLM generations and creating a RM model, how about using another LLM to rate the generations?
This paper proposes this approach to solve this issue, here’s the general overview.

Before we go further, let’s review the RLHF pipeline (bottom pipeline).
RLHF Pipeline Review
In RLHF, we start by using a LLM that is supervized finetuned (SFT) on instruction data or a down stream task.
Given an input x, we sample two responses from the finetuned model r1 and r2. These two responses are shown to human labelers and they will rate them.
We use the results to train a reward model (RM), to output a reward that is as similar to human preference as possible given an input generation.
We finally create a policy initialized by the SFT model weights and train it using reinforcement learning to maximize the reward given by RM.
This is what the usual RLHF pipeline is about and in figure 2, this is the lower part of the diagram.
If you would like to get into more details about RLHF, I recommend this blog.
RLAIF Differences
RLAIF starts diverging from RLHF, after sampling responses from the SFT model. RLHF uses humans to select which response is better but RLAIF suggests using another LLM to do this task.
In this paper we compare both approaches on the task of summarization, the LLM prompt used is therefore like the following.

There are many ways you can get the result from this prompt. For example the output could be “The first summary is better” which could be parsed using heuristics. However forcing the model to output either token “1” or “2” makes it easier to parse and to get the preference distribution.
As you can tell prompting here plays a huge role on the performance of the LLM so the authors of the paper put some effort into trying many things.
Preamble “Base” and “OpenAI”
They experiment with two preambles “Base” and “OpenAI” style.

Base preamble is simple and basically describes the task at hand and defines output format. Notice how base doesn’t explain what “better” means and leaves it up to the LLM.

OpenAI preamble on the other hand is much more expressive. It specifies exactly what a better summary means by focusing on three aspects Accuracy, Coverage and Overall Quality.
Position Bias
LLM are sensitive to the order the candidates are presented in, this can bias the results, hurt the RM and eventually decrease performance (Paper that proves this). To mitigate this, we make two inferences where the order is reversed in the second inference. The results are then averaged.
Chain-of-Thought Reasoning and Self Consistency
Chain of thought reasoning was used to enhance LLM performance by replacing the end “Preferred Summary” with more elaborate ending like “”Consider the coherence, accuracy, coverage, and overall quality of each summary and explain which one is better. Rationale:”
Self Consistency is also used when you sample multiple reasoning paths and aggregate final results.
Reinforcement Learning from AI Feedback
After the data was labelled by the LLM, cross entropy loss is applied to the softmax of the probabilities “1” and “2”.
The difference with the regular pipelines, is that A2C (Advantage Actor Critic) with variation to NLP domain is used instead of PPO (Proximal Policy Optimization) for being simpler but still as effective.
You can view this step as distilling knowledge and AI preference from a much larger LLM to a smaller one.
Evaluation Metrics
AI Labeler Alignment, measures how aligned the AI with human labeler. For example, for input x, human labeler chose r1 as the preferred summary, the AI output 0.6 for r1 and 0.4 for response 2 we transform it into binary 1 for r1 and 0 for r2, both AI and human are aligned that r1 is better.
We apply the same for all inputs and average the results.
Pairwise Accuracy uses a held out set of human labels to evaluate two reward models, one trained with human preference and one with AI. The goal is to see if both RM behave the same and if there’s a significant difference.
Win Rate measures the overall end-to-end performance, human annotators are asked to choose which summary they prefer between RLHF and RLAIF.
Training and Evaluation Results
The chosen model to start with is Palm 2 extra small finetuned on openAI’s TL;DR dataset. As for labeling Palm2 Large was used. The results are presented below

OpenAI + COT with 0 shots prompt yields the best AI labeler alignment. Providing more examples doesn’t improve alignment and even makes it worse.

Self consistency also hurts alignment with more samples.

The bigger the model used for labeling the better the alignment with the labeler. Bigger models are able to generalize better thus they are to choose which summary is best.

Both reward models have “almost” same performance, their pairwise accuracy increases when they train on more preference pairs.
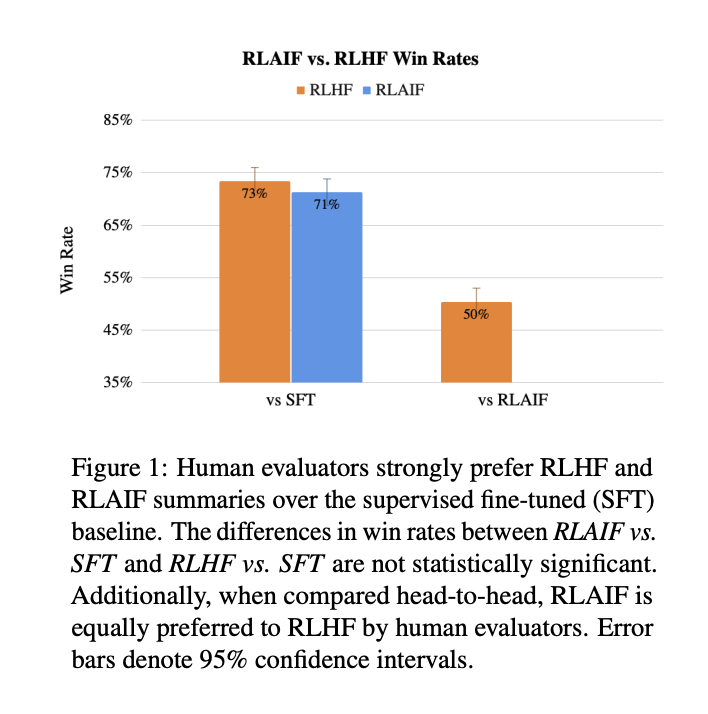
Human evaluators prefer both RLHF and RLAIF on the SFT model. Only 50% preferred RLHF over RLAIF. This means that the other 50% liked RLAIF, so statically they are not different.
My 2 Cents
This paper discusses the possibility of replacing human feedback with AI feedback.
Summary task isn’t a great example to showcase this, in case you have more niche data, you would still need human labelers or specialized models to get preference from.
In my opinion, this approach is good and saves money in case of distilling knowledge and preference from a bigger model which will be easier than setting up a human preference pipeline but it will not replace humans and will not solve the RLHF bottleneck issue.
Paper: https://arxiv.org/pdf/2309.00267.pdf
Clap, Follow and Comment if you like the article!
Stay In touch by connecting via LinkedIn Aziz Belaweid or GitHub.